
The Definitive Guide to AI Agent Memory Benchmarks: How to Measure What Matters
Everyone is building AI agents with memory. Almost nobody is measuring whether that memory actually works.
After spending considerable time evaluating memory-augmented agent systems in production, one pattern stands out: teams invest months engineering sophisticated extraction, consolidation, and retrieval pipelines – then validate them with nothing more than vibes and manual spot-checks. The absence of rigorous benchmarking is the single biggest blind spot in the agent memory ecosystem today.
This post is a comprehensive guide to the current state of agent memory benchmarks – the evaluation scenarios that exist, the metrics that matter, the open-source tools available, and the strategic framework for choosing the right benchmark for the right capability. The goal is to equip engineering teams with a practical decision-making guide for measuring memory quality at every layer of the stack.
Why Memory Evaluation Is Fundamentally Different
Evaluating agent memory is not the same as evaluating an LLM’s factual knowledge or a RAG pipeline’s retrieval accuracy. Standard NLP benchmarks typically operate on single-turn, static inputs. Agent memory, by contrast, involves information dispersed throughout extended, multi-turn interactions within evolving system environments.
A memory-enabled agent must do three things well, and each demands its own evaluation methodology:
Remember the right things – the system must extract meaningful facts from noisy conversation histories while discarding pleasantries, filler, and irrelevant details.
Find the right memories at the right time – when a relevant memory exists, the retrieval system must surface it within a strict latency budget, typically under 200 milliseconds.
Use memories to actually improve task performance – the ultimate test is whether memory makes the agent measurably better at its job, not just whether the database has correct entries.

This three-layer evaluation framework is the starting point for any serious memory assessment. But the question remains: what benchmarks exist to actually measure these capabilities?
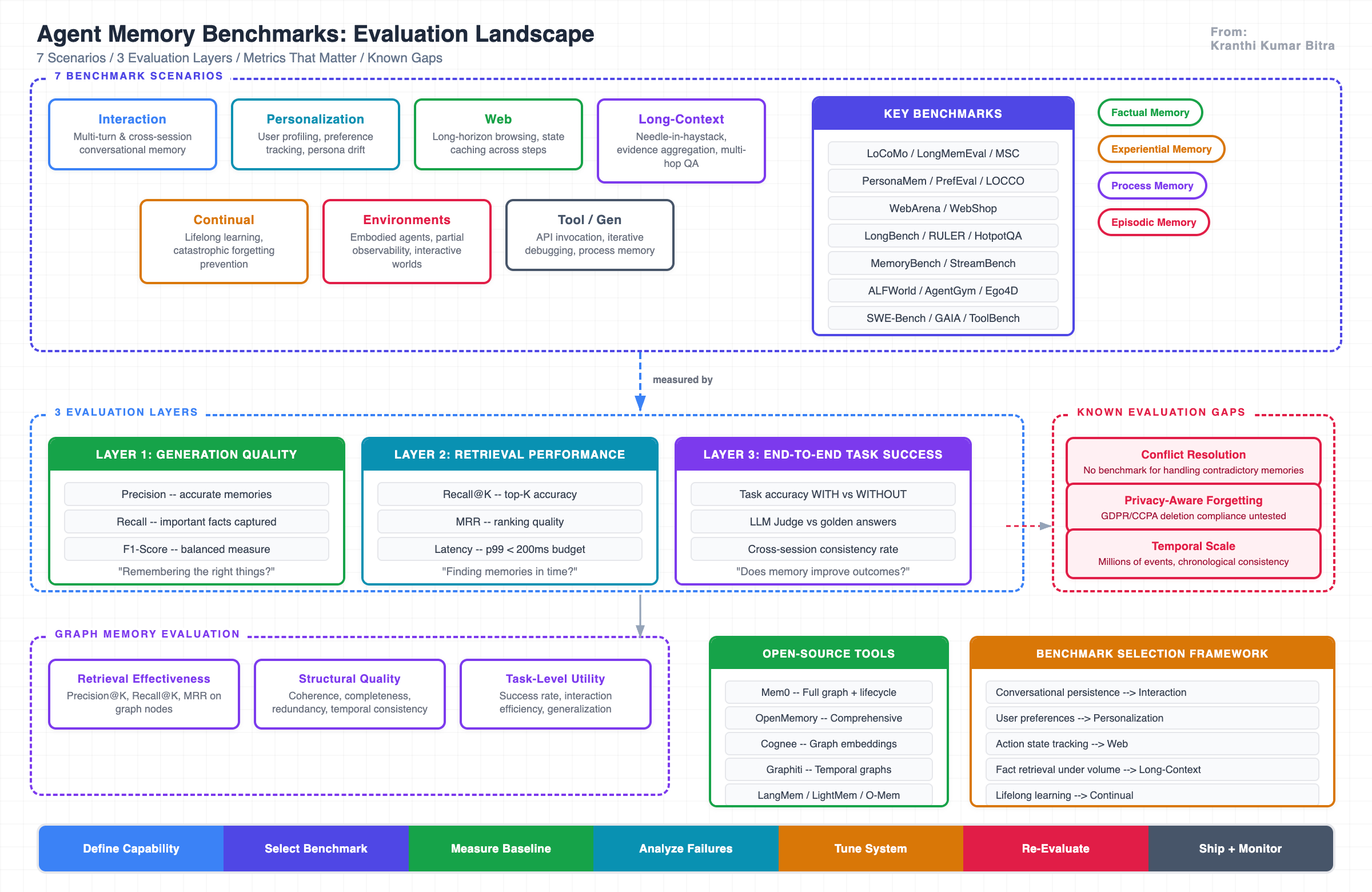
The Benchmark Landscape: A Scenario-Based Taxonomy
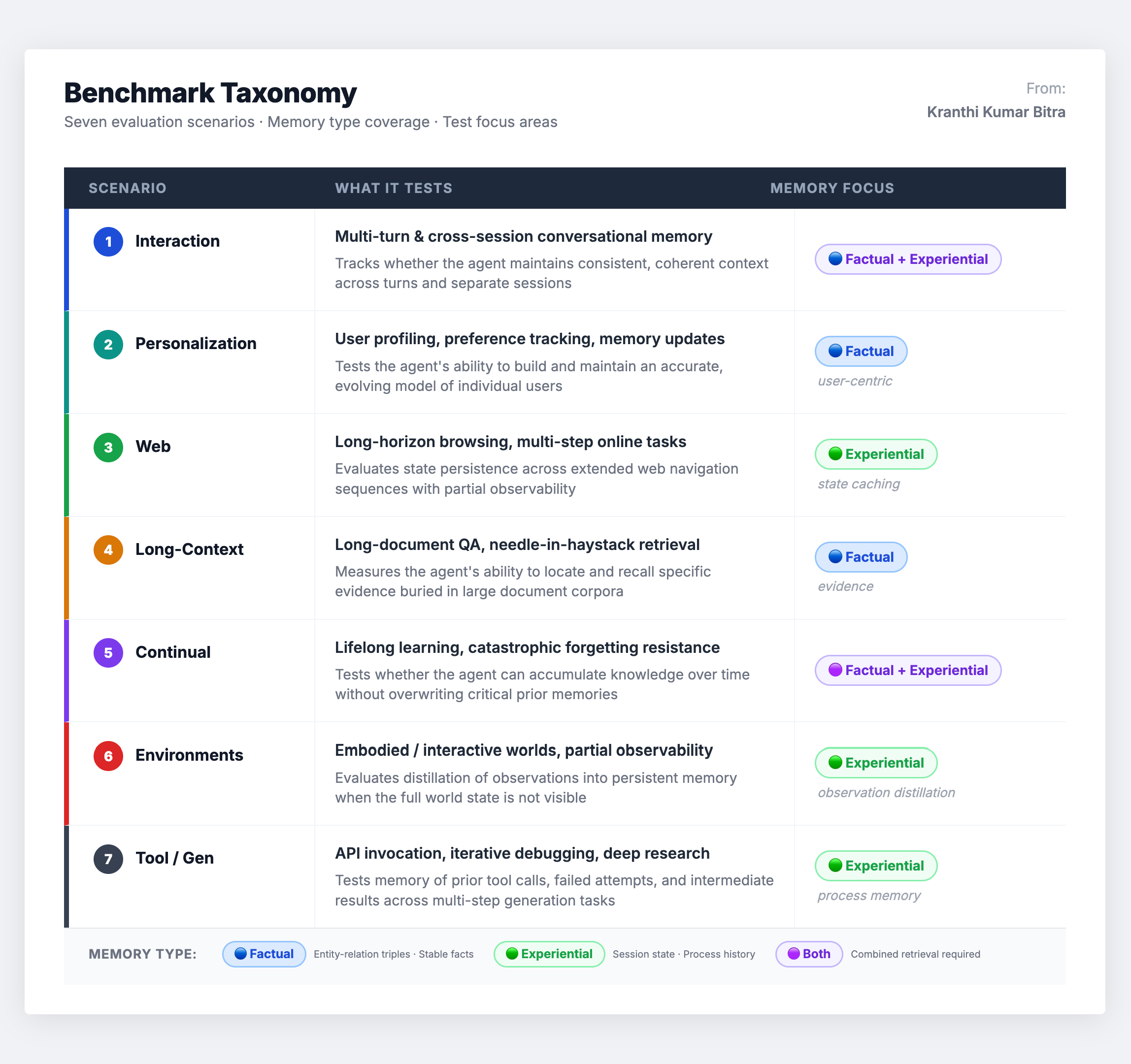
The current landscape of agent memory benchmarks can be organized into seven distinct evaluation scenarios. Each scenario tests a different dimension of memory capability, uses different interaction patterns, and surfaces different failure modes. Understanding this taxonomy is essential for selecting the right benchmark for a specific use case.
Let us walk through each scenario in depth.
Scenario 1: Interaction Benchmarks – Conversational Continuity
Interaction benchmarks are the most directly relevant for building conversational agents. They test whether an agent can maintain continuity across multi-turn and cross-session dialogues – whether information introduced early in a conversation (or in a prior session) is accurately recalled and applied later.
This is the largest benchmark category, and for good reason. The core capabilities being tested – long-range context retention, cross-session consistency, and retrieval of user-provided facts during ongoing dialogue – are table stakes for any assistant-style agent.
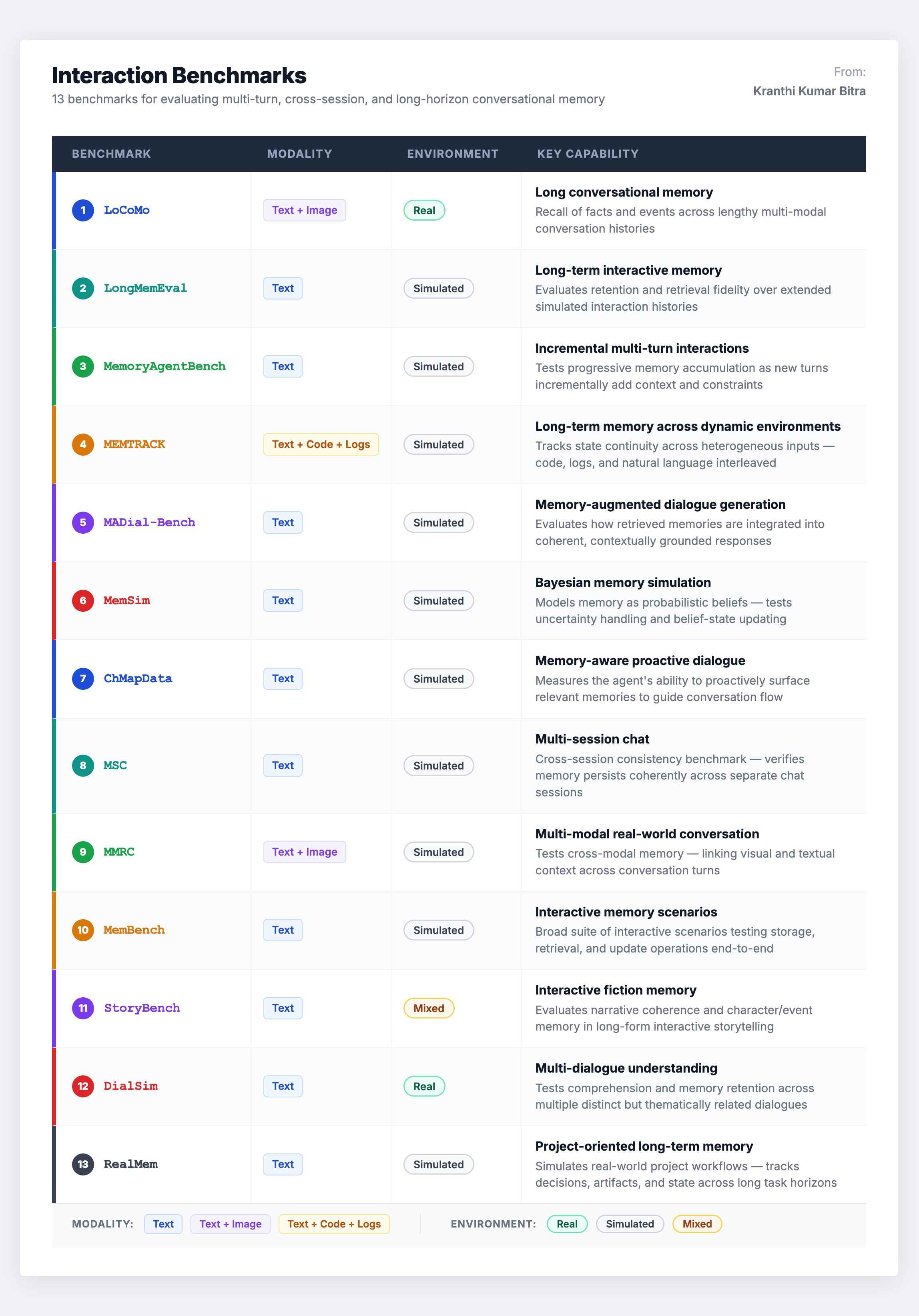
Common metrics across these benchmarks include task-level accuracy, retrieval-oriented measures like Recall@K, and dialogue-level consistency rates. Some also track success rates over multi-turn tasks to assess whether recalled information is effectively integrated into responses.
The notable gap: Many interaction benchmarks lack explicit supervision for memory updates when dealing with conflicting facts. The mechanism by which agents overwrite or forget outdated information is less systematically evaluated than simple recall ability. This is a significant blind spot – in production, graceful conflict resolution is often more important than raw recall.
Scenario 2: Personalization Benchmarks – User Identity Persistence
Personalization benchmarks examine a more specific capability: whether an agent can build a stable user model and integrate new user information over time. They focus on managing persistent user-centric facts and profile attributes – names, preferences, stated constraints, and evolving goals.
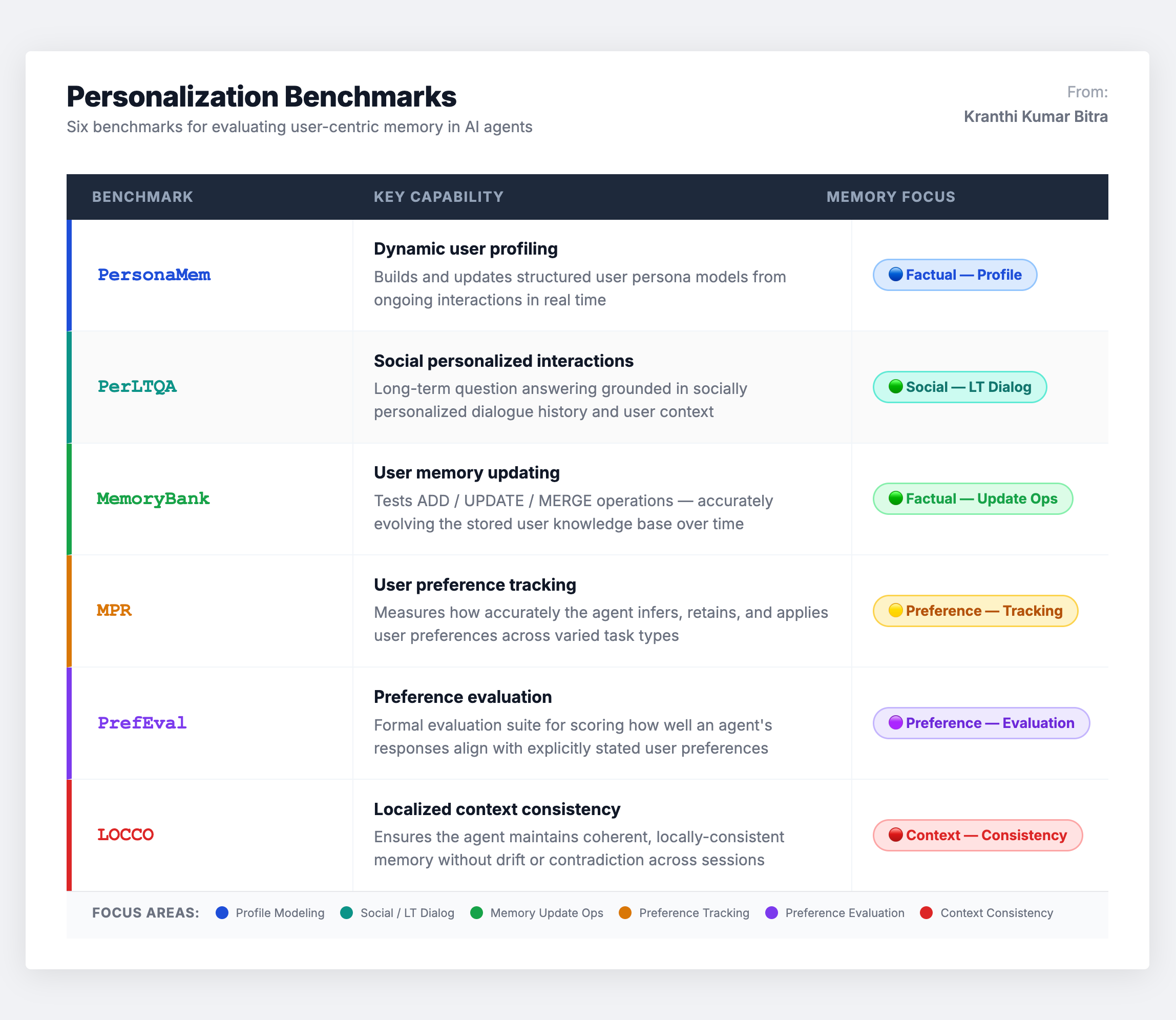
The primary real-world challenge these benchmarks address is persona drift – the failure mode where an agent gradually forgets or contradicts previously established preferences. In production, this manifests as the agent asking a user for their dietary restrictions for the third time, or recommending flights that violate constraints stated weeks ago.
The notable gap: Current personalization benchmarks frequently rely on clear, explicit supervision regarding what should be stored. In actual deployment, selective writing (deciding what is and is not worth remembering) and privacy-aware retention (what must be forgotten for compliance) are far more nuanced challenges that remain underaddressed.
Scenario 3: Web Benchmarks – State Tracking at Scale
Web benchmarks evaluate memory within extended action trajectories where agents must track environmental states and intermediate results across many steps. These include e-commerce interactions, functional website navigation, complex browsing routines, and multi-hop web interactions.
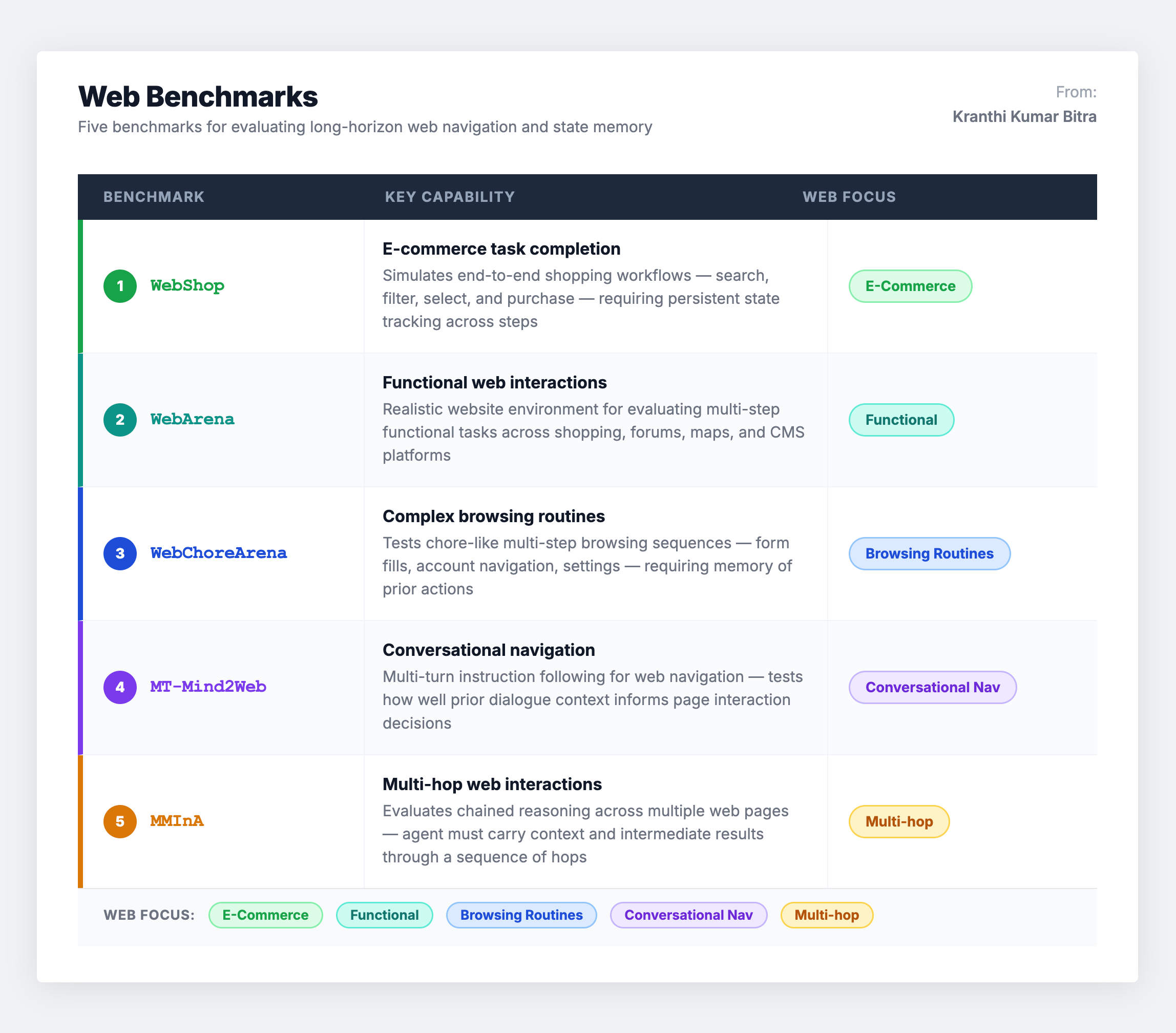
These tasks place heavy demands on experiential memory because agents must often cache page states to prevent redundant actions. They also highlight the necessity of resource-efficient memory – excessive tool calls lead to high operational costs, making memory optimization a direct cost-reduction lever.
The notable gap: Success in web benchmarks can sometimes be achieved through simple heuristics, making it difficult to isolate the specific impact of memory. Controlled settings that limit memory capacity are needed to properly attribute performance gains to the memory system rather than other agent capabilities.
Scenario 4: Long-Context Benchmarks – Retrieval Under Volume
Long-context benchmarks measure agent performance under high-volume inputs and retrieval-intensive settings. These include multi-step evidence aggregation, multi-hop reasoning, needle-in-a-haystack retrieval, and hallucination evaluation under long contexts.
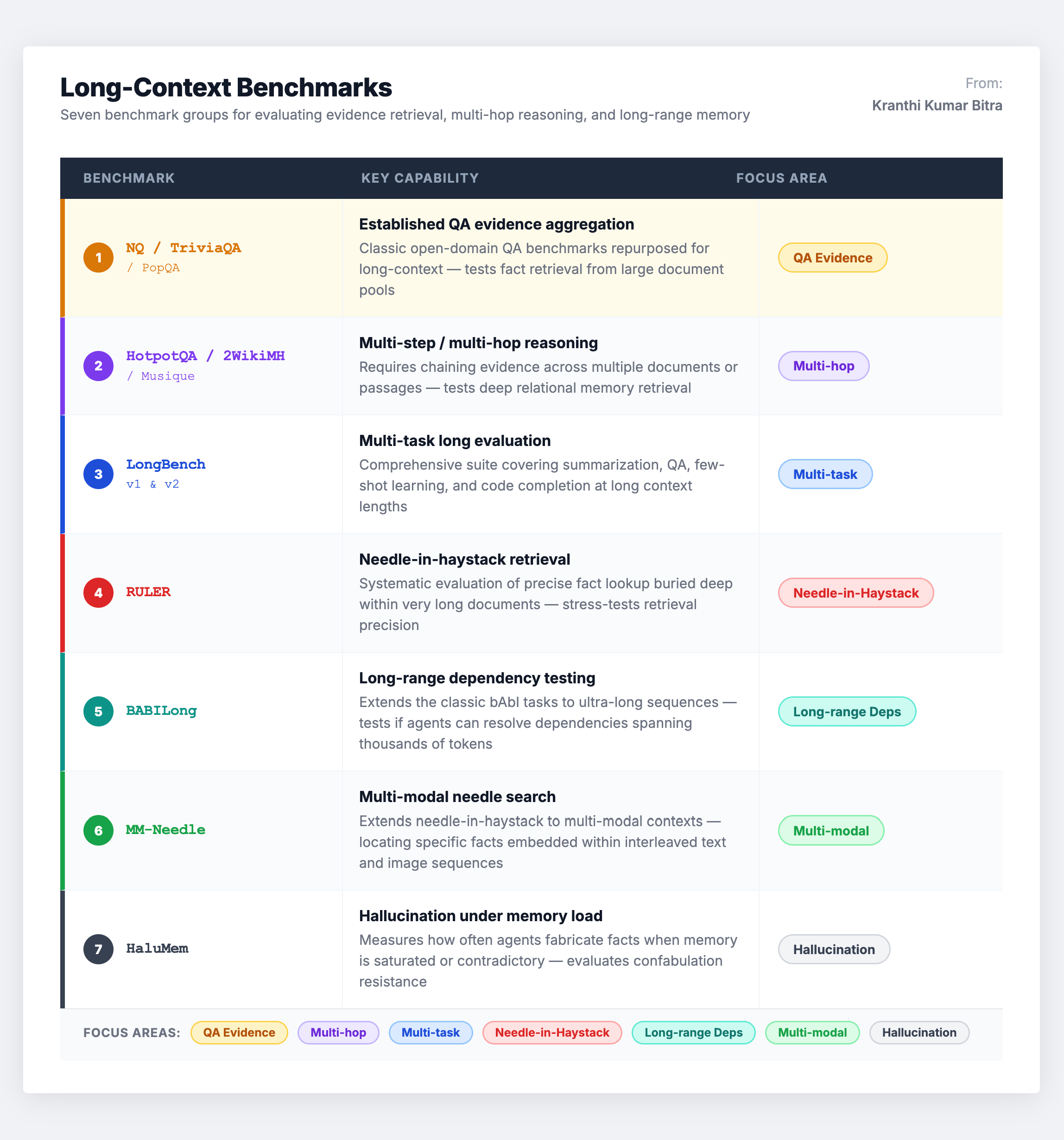
While these benchmarks are essential for modeling evidence access, they carry an important caveat: many are single-turn and do not require the agent to actively write to a persistent memory store. This means they potentially conflate long-context processing (a model capability) with dedicated memory mechanisms (a system capability). A model that performs well on LongBench may still have a terrible memory system, because it never had to create, manage, or evolve any memories – it just had a large enough context window to brute-force the answer.
Scenario 5: Continual Learning Benchmarks – Forgetting vs. Growing
Continual benchmarks assess whether agents can improve over time without experiencing catastrophic forgetting – maintaining proficiency in earlier tasks while acquiring new knowledge under streaming or sequential task distributions.
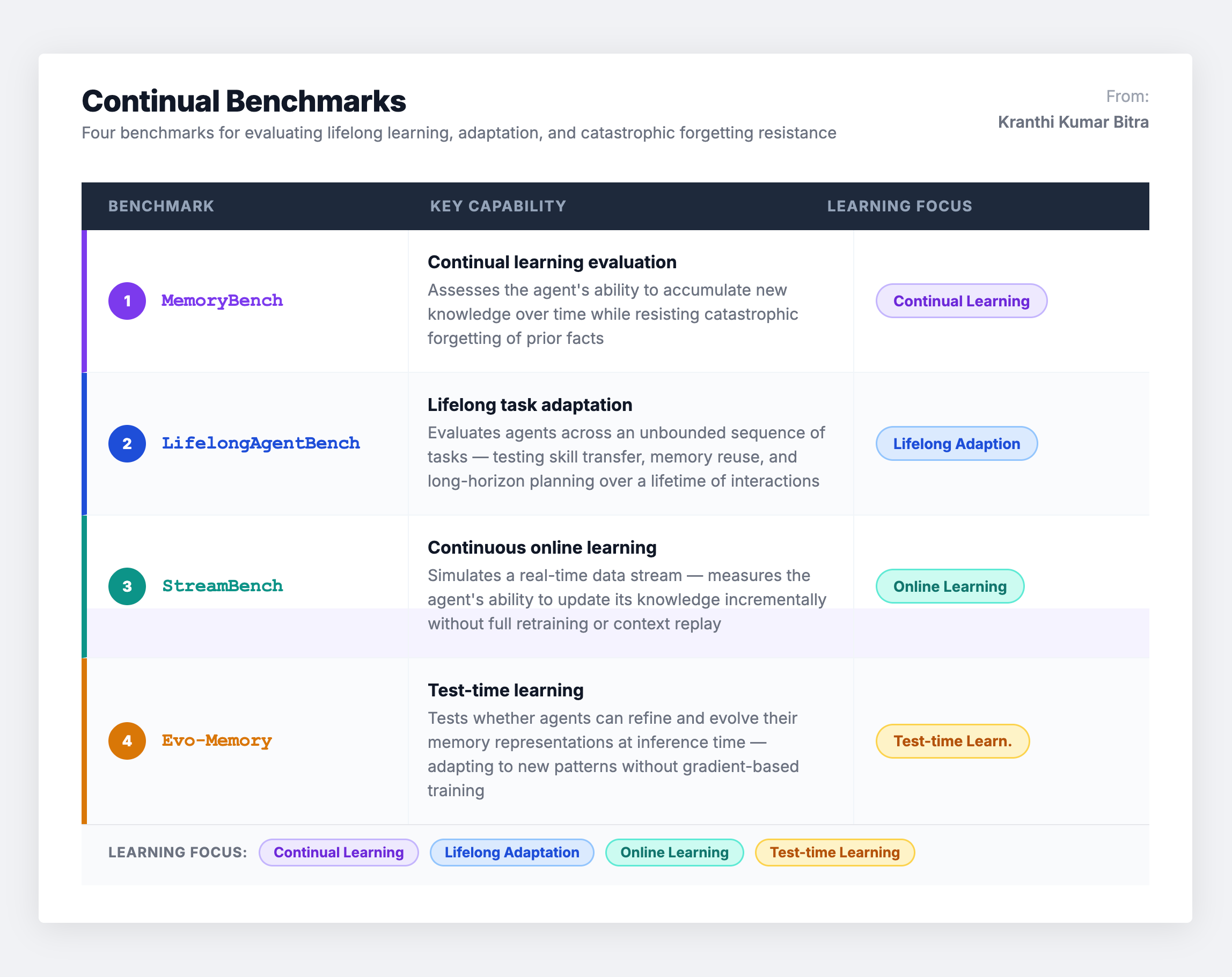
This category represents lifelong memory in its strictest sense. It is arguably the most important for production systems that must operate over months or years, yet it is the least standardized. Metrics for forgetting and transfer gains vary significantly across benchmarks, and it is often difficult to determine whether performance gains stem from parametric updates (the model itself changing) versus retrieval over past logs (the memory system working). Ablation studies that cleanly isolate memory contribution remain rare.
Scenario 6: Environment Benchmarks – Embodied Memory
Environment-based benchmarks evaluate agents in simulated or physical interactive settings where memory must distill observations under partial observability – the agent cannot see everything and must remember what it has already learned about the world.
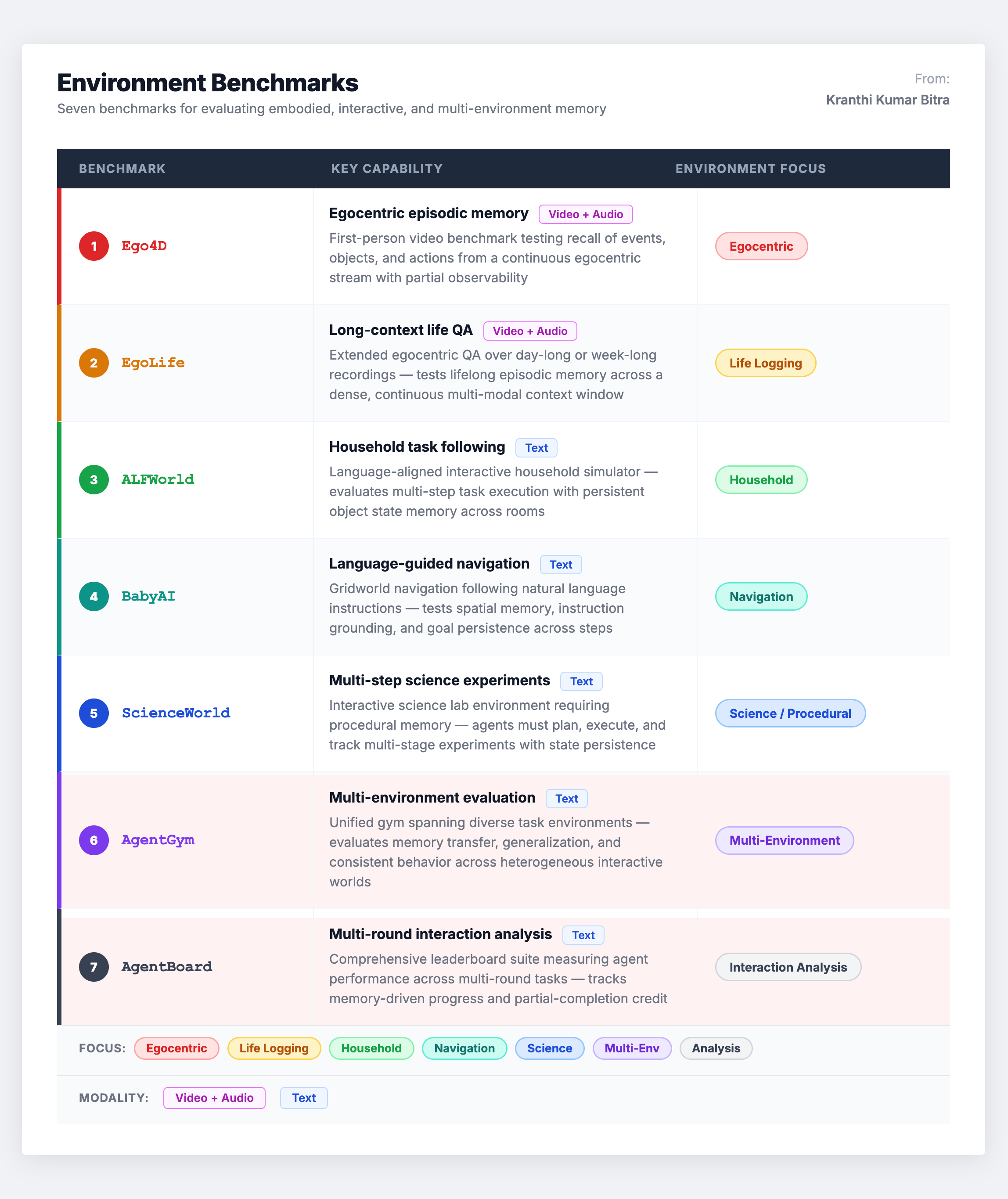
These benchmarks primarily test experiential memory and robustness across environmental variations. The challenge: since performance is tied to environment-specific skills, claiming memory-related benefits requires carefully controlling for planning and tool-use variables. An agent might succeed because it has a better planner, not better memory.
Scenario 7: Tool/Gen Benchmarks – Process Memory
Tool and generation benchmarks evaluate memory within workflows involving external APIs and iterative reasoning. They emphasize process memory – the ability to retain intermediate hypotheses, failed attempts, and successful strategies across multi-step workflows.

These tasks underscore operational issues like traceability (can the agent explain why it made a particular tool call based on memory?) and the financial cost of retries (can better memory reduce redundant API calls?). Evaluation complexity is high because success hinges on environment stability and the design of specialized scoring scripts.
Graph-Based Memory: A Specialized Evaluation Framework
With the rise of graph-based memory architectures – knowledge graphs, temporal graphs, hypergraphs, and hybrid structures – a new dimension of evaluation has emerged. Graph memory demands assessment not just of what the agent remembers, but of how that knowledge is structurally organized.
The evaluation framework for graph-based memory operates across three complementary dimensions:
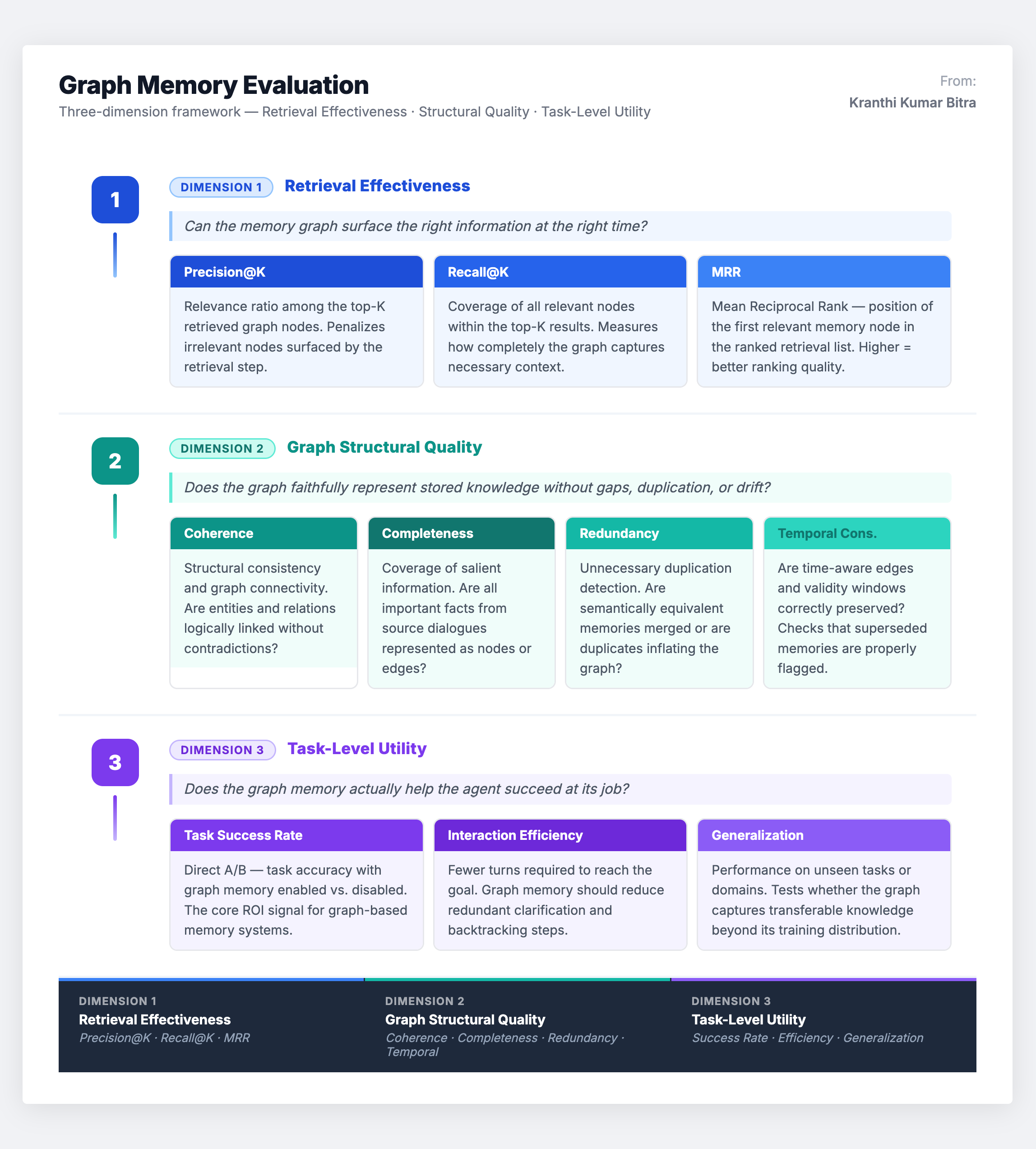
The structural quality dimension is unique to graph-based systems. A vector database either returns a relevant embedding or it does not – there is no notion of structural coherence. But a knowledge graph can have disconnected components, contradictory triples, redundant paths, or broken temporal chains, all of which degrade downstream reasoning even when individual memories are technically correct. Evaluating these structural properties is essential and often overlooked.
The Open-Source Library Landscape
Beyond benchmarks, the open-source ecosystem for building agent memory systems has matured significantly. Understanding which libraries support which capabilities helps teams select the right foundation. Here is how the major options compare across key functional dimensions:

Several patterns emerge from this comparison:
Mem0 and OpenMemory are the most comprehensive graph memory tools, supporting the full spectrum of construction, interaction-driven updates, lifecycle management, temporal awareness, and graph management. For teams building graph-based memory from scratch, these are the strongest starting points.
Cognee provides queryable graph embeddings – useful when the primary need is structured knowledge retrieval over a graph representation. Graphiti enables temporal graph reasoning for multi-step planning, making it well-suited for agents that need to reason about sequences of events.
LangMem, LightMem, and O-Mem are non-graph systems with memory construction predominantly driven by interaction or session data. They support retrieval fundamentally based on embedding similarity – adequate for many production use cases, but lacking the structured traversal capabilities of graph-based alternatives.
Memori and MemMachine are lightweight, modular options that prioritize ease of integration. They are useful for teams that want basic memory functionality without the overhead of a full graph pipeline.
Strategic Benchmark Selection: A Decision Framework
Choosing the right benchmark is not about picking the most cited one. It requires mapping the specific memory capability being developed to the scenario that best evaluates it. Here is the decision framework used in practice:
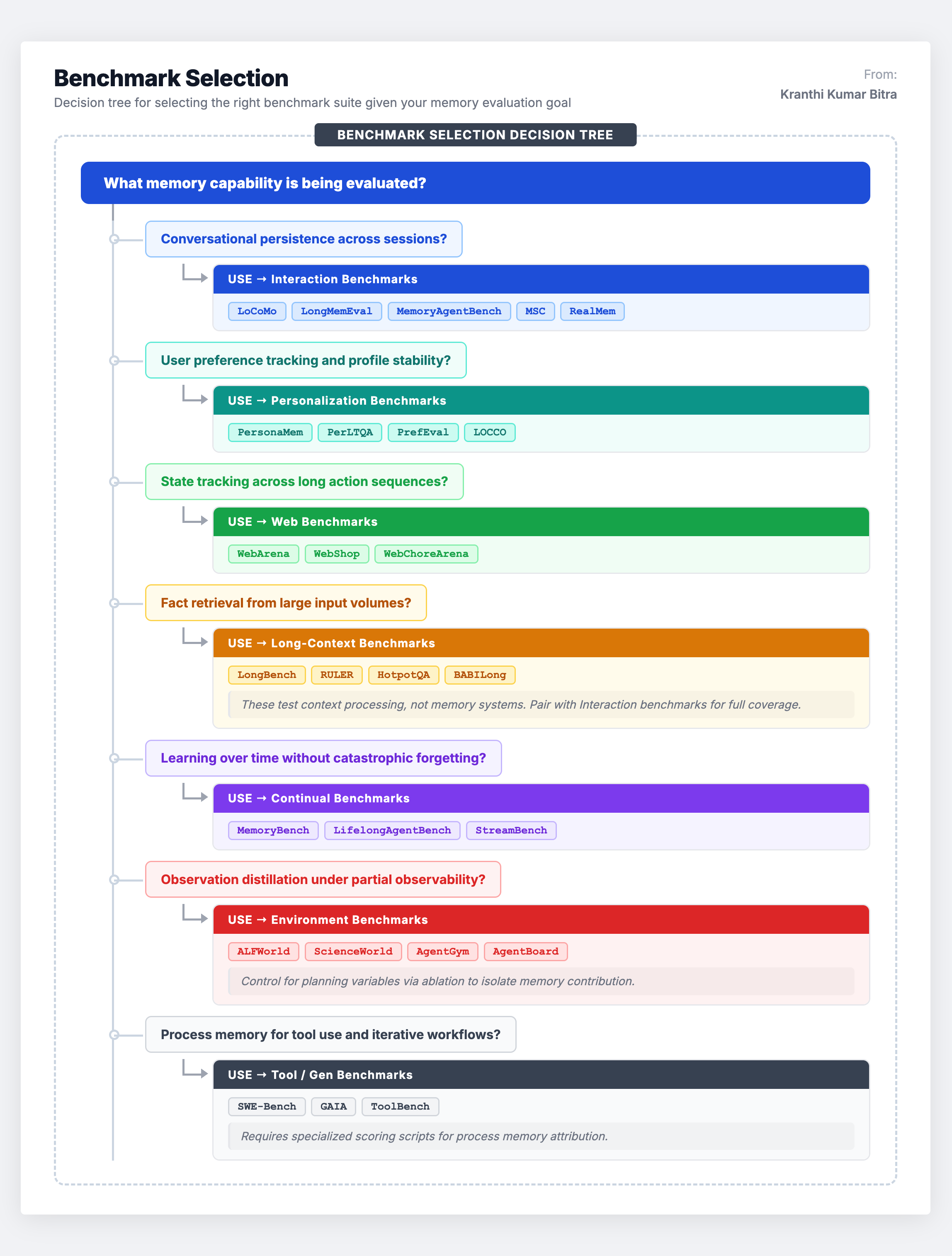
A critical principle: never evaluate memory in isolation. The best evaluation strategies combine at least two scenarios – for example, pairing Interaction benchmarks (to test conversational persistence) with Personalization benchmarks (to test profile stability) gives a much more complete picture than either alone.
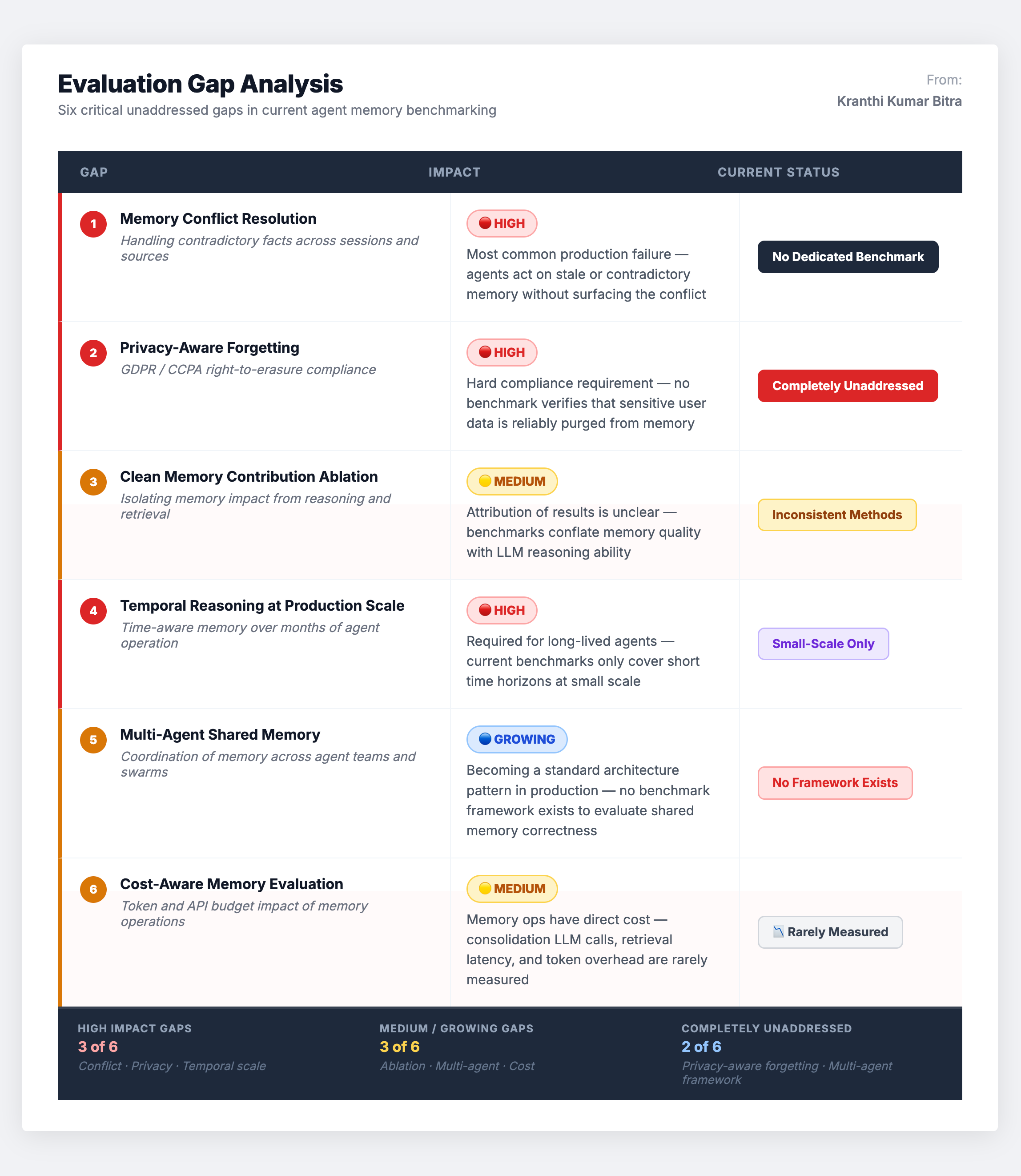
The Gaps That Still Need Closing
Despite the progress in this space, significant evaluation gaps remain. Being aware of these gaps is important for interpreting benchmark results honestly and for identifying areas where internal evaluation suites need to supplement public benchmarks.
Memory conflict resolution is underaddressed. Most benchmarks test whether an agent can recall a fact, but very few test whether it can gracefully handle contradictory information – resolving a conflict between what the user said last week and what they said today. In production, this is one of the most common failure modes.
Privacy-aware memory management has no dedicated benchmark. Real-world systems must selectively forget information for compliance (GDPR right-to-deletion, CCPA opt-out), yet no existing benchmark tests this capability. The closest analogues are personalization benchmarks, but they focus on preference accuracy, not data governance.
Ablation methodologies are inconsistent. Many benchmark results make it difficult to isolate memory’s specific contribution. An agent that succeeds at a web task might have a great planner, great memory, or both. Without controlled ablation studies that disable or degrade the memory system, attribution of results to memory is unreliable.
Temporal reasoning under scale is untested. Current temporal graph benchmarks work at modest scale. There are no established benchmarks for testing temporal queries across millions of memory events while maintaining chronological consistency – a requirement for any system operating over months or years of user interactions.
Multi-agent memory sharing is uncharted territory. As multi-agent architectures become standard, the challenge of shared memory – where multiple agents contribute to and consume from a common knowledge base – has no dedicated evaluation framework. This involves not just retrieval accuracy but consistency, conflict resolution across agents, and access control.
Building an Internal Evaluation Pipeline
Given the gaps in public benchmarks, production teams should build internal evaluation pipelines that complement public benchmarks with domain-specific tests. Here is the pipeline architecture that works in practice:
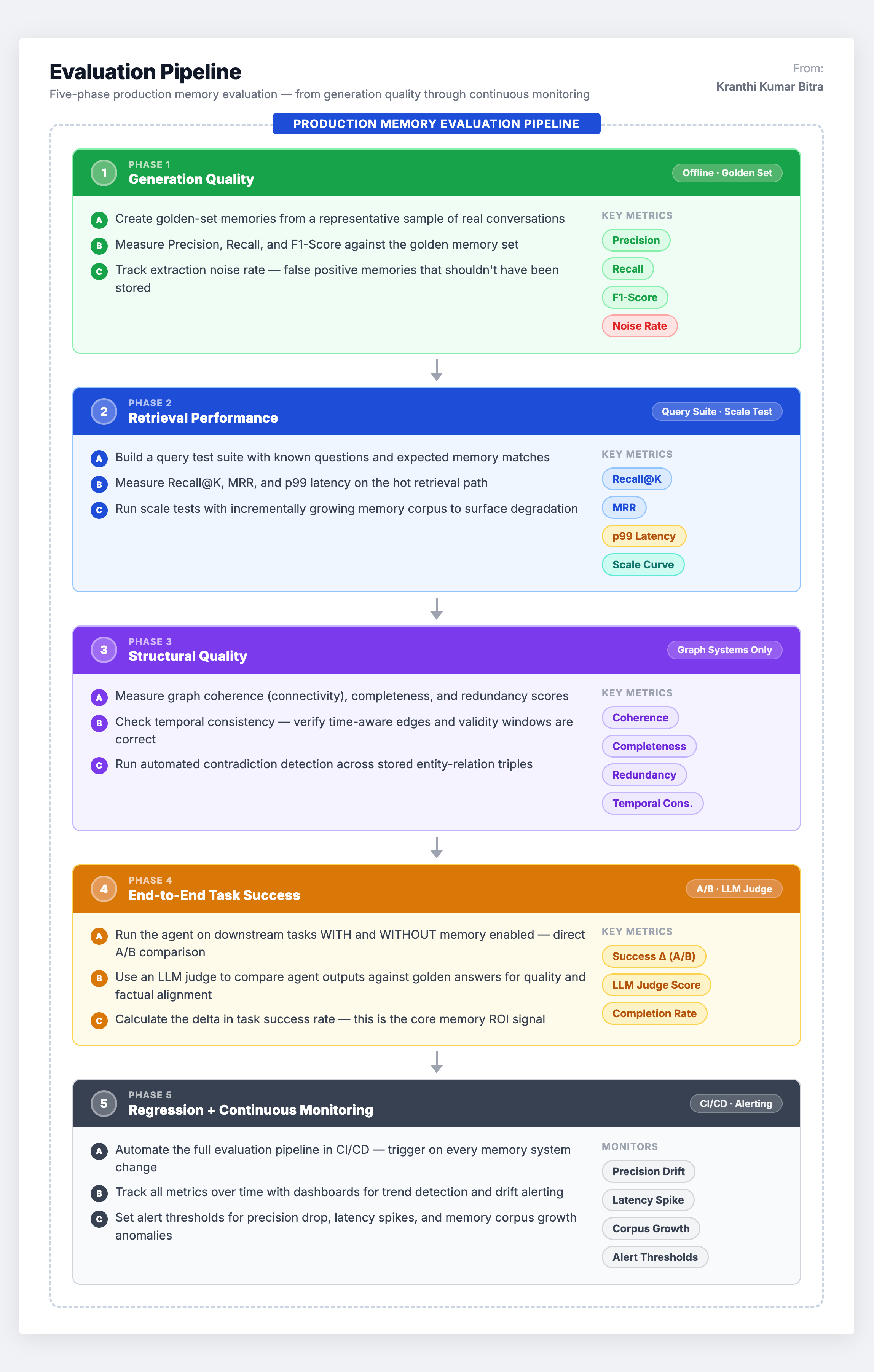
Evaluation is not a one-time event. It is an engine for continuous improvement – establishing baselines, analyzing failures, tuning the system (refining extraction prompts, adjusting retrieval algorithms, modifying consolidation rules), and re-evaluating to measure impact. The metrics provide the data needed to identify weaknesses and systematically enhance the memory system over time.
Closing Perspective
The agent memory benchmark ecosystem is maturing rapidly, but it is still far from complete. The seven-scenario taxonomy – Interaction, Personalization, Web, Long-Context, Continual, Environments, and Tool/Gen – provides solid coverage of the major capability dimensions, but significant gaps remain in conflict resolution, privacy-aware forgetting, temporal scale, and multi-agent coordination.
For engineering teams building production memory systems, the path forward involves three concurrent strategies: leverage existing public benchmarks for well-covered capabilities (conversational persistence, retrieval accuracy), build internal evaluation suites for domain-specific requirements and uncovered gaps, and advocate for community-driven benchmark development in the areas where no good evaluation tools exist.
The teams that invest in rigorous memory evaluation now will be the ones that ship agents capable of genuine long-term intelligence – not just impressive demos that crumble after the third session.
Memory is only as good as the measurement system behind it. Start measuring.
This analysis reflects architectural understanding and evaluation methodology developed through hands-on experience building and benchmarking memory-augmented agent systems across production environments.