
Voice-Native Edge AI: Designing Intelligence for the Physical World
How deploying a small language model on constrained hardware forces a discipline that cloud AI never had to develop
When we talk about AI interfaces, the conversation almost always assumes abundant compute, reliable connectivity, and a tolerant user who will wait a few seconds for a cloud round-trip. Strip those assumptions away — deploy on a 4GB embedded controller in a field with no cellular signal, where the consequence of a wrong command is a flooded field or a machine stop that costs thousands of dollars per hour — and every design decision changes.
This is the design space of edge AI interfaces: systems that run inference fully on-device, operate across degraded or absent connectivity, must respond in milliseconds for safety-critical interactions, and serve operators who are not knowledge workers sitting at a desk but skilled workers whose hands and attention are often elsewhere.
The principles that emerge from this design space are not niche engineering concerns. They are, arguably, the principles that all AI interfaces will eventually need to develop as AI moves from the browser into the physical world — into industrial equipment, medical devices, vehicles, agricultural machinery, and infrastructure systems. Cloud-first AI borrowed interface patterns from consumer software. Edge AI has to invent its own.
The Central Constraint: No Escape Hatch
Cloud AI systems have a fundamental luxury: if the model is uncertain, if the input is ambiguous, if the system doesn’t know what to do — it can stall, send the request to a larger model, consult a retrieval system, or simply produce a vague response and wait for the user to clarify. The cost of hedging is measured in tokens and milliseconds.
Edge AI systems have no such luxury. The hardware has a fixed envelope. The model that fits in that envelope is the model that runs. There is no larger model to escalate to. There is no cloud fallback that preserves the real-time safety contract. And crucially, the cost of hedging is not measured in tokens — it is measured in consequences to the physical system the AI is controlling.
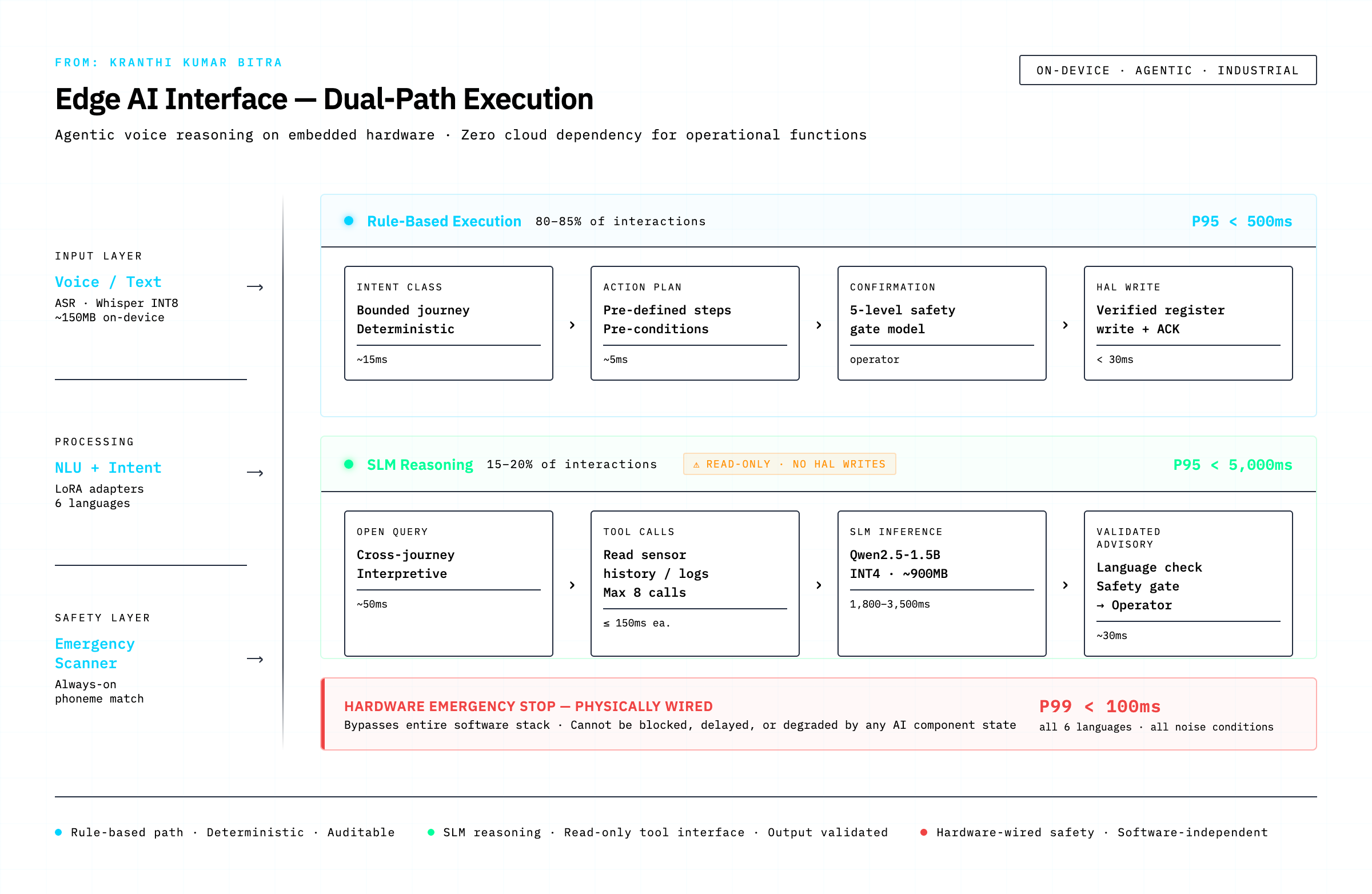
This constraint is generative. Facing a hard budget forces a design discipline that abundant resources obscure. The most important discipline it forces is what we call the two-path execution model — a fundamental architectural split that, once understood, turns out to be the right answer for a large class of AI interface problems.
The Two-Path Execution Model
The insight is simple: not all operator interactions are the same kind of thing.
The vast majority — 80 to 85 percent, in a well-designed domain-specific interface — are structured requests that map cleanly onto a known operation. “Set the speed to 70 percent.” “Start the pivot running forward.” “What’s the current water pressure?” These are deterministic. The same input always produces the same output. They require zero reasoning. They do not need a language model at all.
The remaining 15 to 20 percent are reasoning requests — questions that require interpretation across multiple data sources, causal analysis, or synthesis of context that isn’t captured in any single sensor reading. “Why has the flow rate been declining this week?” “Given the rainfall we’ve had, what irrigation depth should I target?” “Something seems off with tower 3 — what do you think is happening?” These require genuine reasoning. A template cannot answer them. A rule cannot answer them. A language model is the right tool.
The two-path model separates these cleanly:
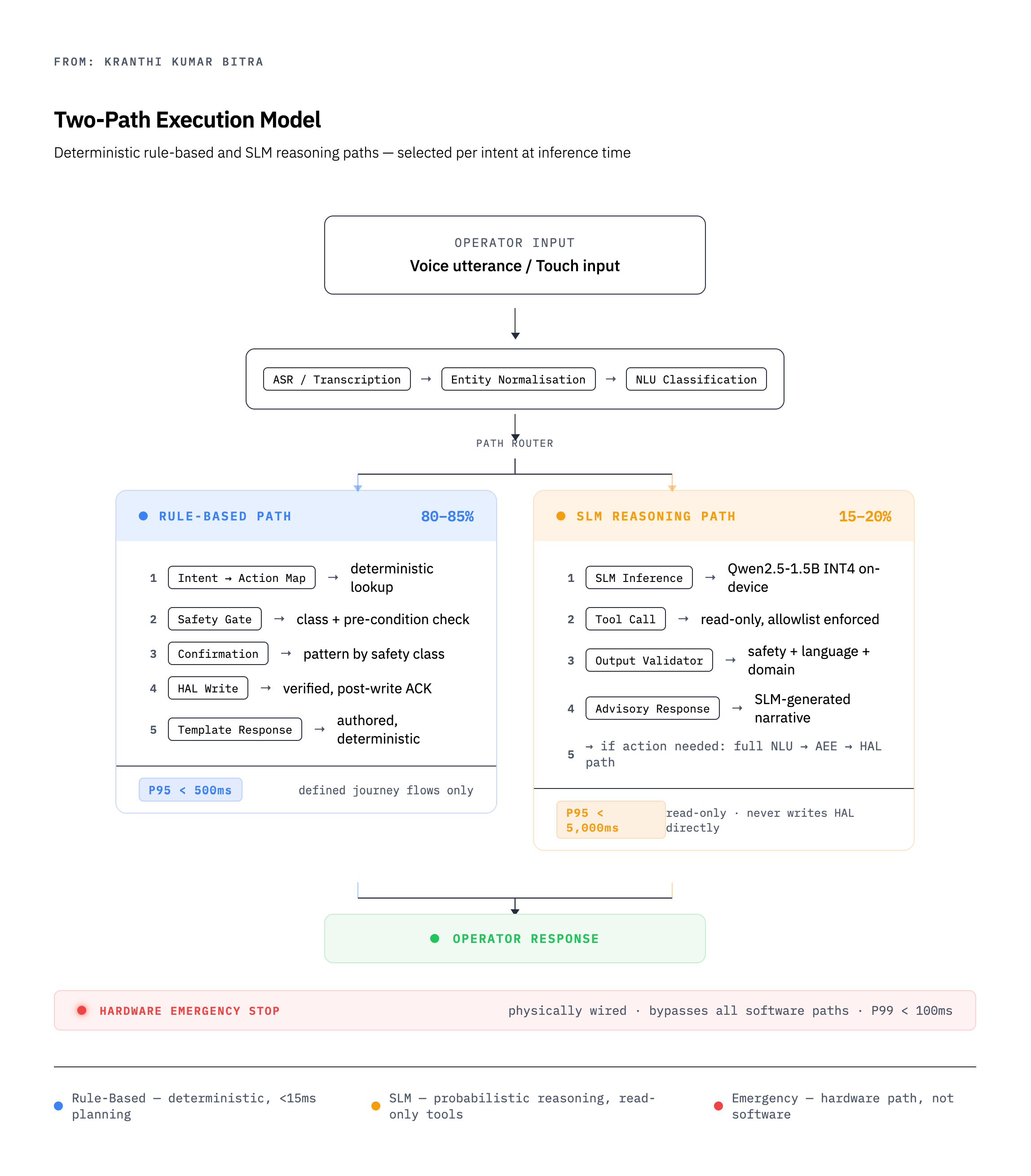
The rule-based path handles the structured 80 percent. It is fast (P95 under 500ms end-to-end, including ASR), deterministic, fully auditable, and executes without any language model involvement. Its planning time is measured in single-digit milliseconds.
The SLM reasoning path handles the interpretive 20 percent. It is slower (P95 under 5 seconds), probabilistic, and generates free-form narrative. Critically, it is read-only — it queries data stores and sensors but can never write to the hardware layer directly. Any action it recommends must travel back through the full rule-based confirmation flow before touching the physical system.
This separation has a counterintuitive consequence: it makes the system more capable than a unified LLM approach, not less. The rule-based path is faster and more reliable at structured commands than any language model can be, because it doesn’t have to do what language models do — it just does a lookup. The SLM is freed to do only what language models are actually good at: reasoning across ambiguous, multi-dimensional information.
The common alternative — routing everything through a single large model — produces a system that is mediocre at structured commands (too slow, occasionally wrong), mediocre at reasoning (constrained by the hardware budget), and lacks the clear safety boundary that the two-path model provides by construction.
On-Device Inference Stack: What Actually Fits
Running a useful AI system within the constraints of an embedded controller requires a clear understanding of what the hardware can sustain. Not aspirational numbers — sustained inference under real thermal and memory conditions during long field operations.
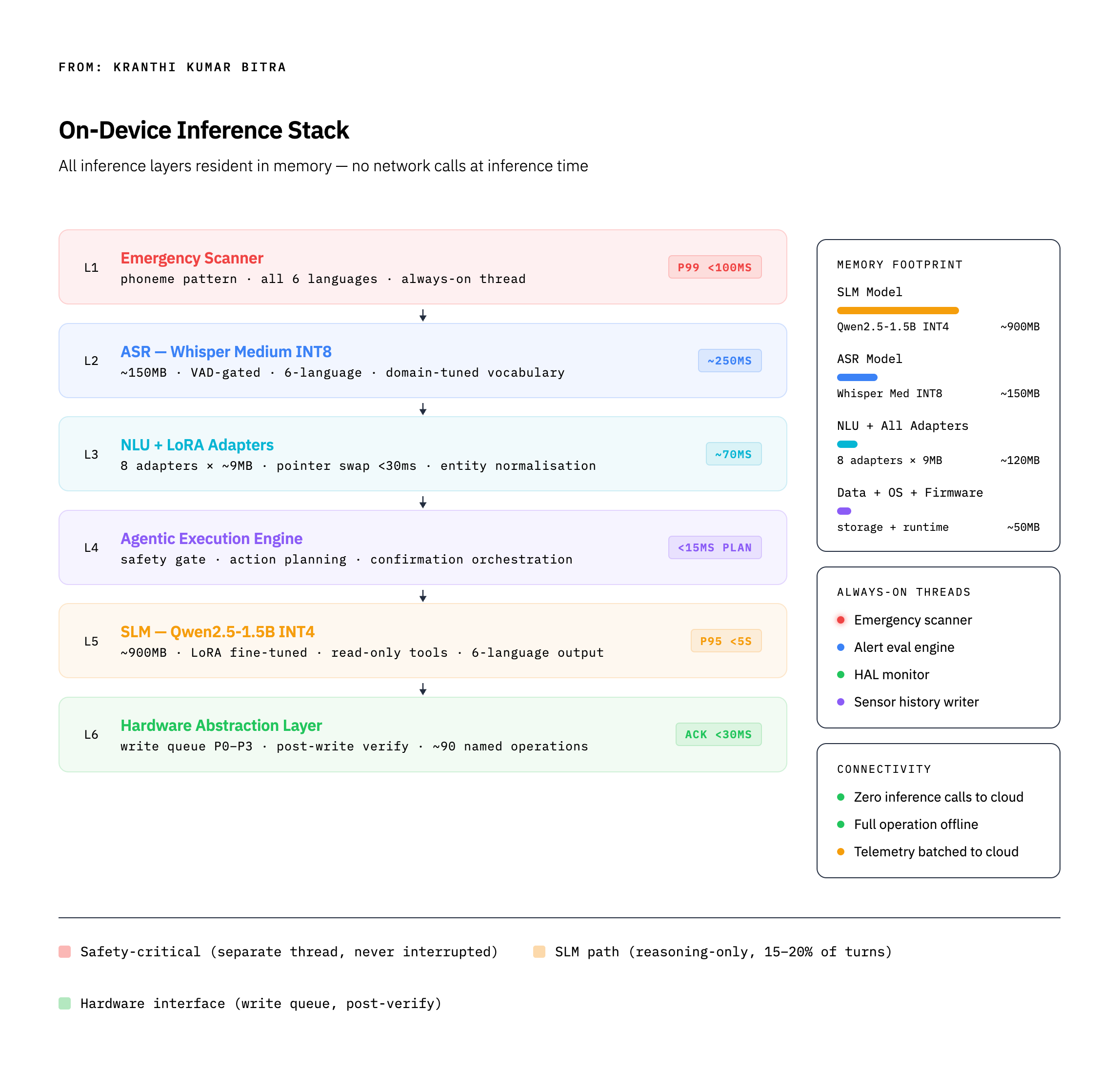
A practical on-device inference stack for a voice-native interface has four key components:
The emergency scanner runs in a dedicated thread that is never preempted by inference load. Its job is phoneme-level pattern matching against a small set of safety-critical keywords. It has no awareness of language model state, session context, or what the system is currently doing. It fires in under 100ms regardless. This is not an AI component — it is a real-time signal processing component that happens to be part of the AI interface. Its physical wiring to the hardware emergency stop bypasses the entire software stack. No software failure can disable it.
The ASR layer (Whisper Medium, INT8 quantised) handles the speech-to-text conversion. At roughly 150MB, it is a significant fraction of the memory budget but provides the domain quality and multilingual coverage that smaller models cannot. It is VAD-gated — it does not run on silence — and its output feeds the entity normalisation layer before NLU.
The NLU layer with LoRA adapters performs intent classification and entity extraction. The key architectural decision here is the adapter design: a base multilingual NLU model with per-language, per-role LoRA adapters (~9MB each), all loaded into RAM simultaneously. Switching languages is a pointer operation, not a model reload. The adapter for a Spanish-speaking operator in the field switches in under 30 milliseconds.
The SLM (a 1.5B parameter model, INT4 quantised, ~900MB) is the reasoning engine. At this parameter count and quantisation level, it fits in the remaining memory envelope and produces inference in 1.5–2.5 seconds on constrained hardware — acceptable for the 15–20% of interactions that require it, where operators intuitively understand that analysis takes longer than a simple command.
The total inference stack occupies approximately 1.2–1.3GB of working memory. The SLM is the dominant consumer. This is an important design constraint: the SLM budget sets the floor on the hardware specification for the entire system.
Three Independent Latency Contracts
One of the most important conceptual shifts in edge AI interface design is treating latency not as a single system metric but as a set of independent contracts, each governed by different principles.

Contract 1 — Safety contract: The emergency stop path must complete in under 100ms at P99. This is not a performance target — it is a safety specification. It is tested with 9,000 repetitions across six languages and three noise conditions. It must hold under full CPU load, during SLM inference, during data writes, during anything. The only thing that can defeat it is a hardware failure. Software load is not an excuse.
Contract 2 — UX contract: The rule-based path must complete in under 500ms at P95. This is the threshold below which operators perceive a response as nearly immediate. Breaching it consistently will cause operators to lose confidence in voice interaction and revert to manual navigation — a real failure mode for AI interfaces in field environments where the physical alternative is always present.
Contract 3 — Analysis contract: The SLM reasoning path must complete in under 5 seconds at P95, with a hard timeout at 6 seconds. This is a different category of expectation — operators asking “why is the flow declining?” are not expecting an instant answer. They are expecting a thoughtful one. The 5-second window is shaped by field observation of how long operators will wait for a response they believe is genuinely analytical.
These three contracts must be governed independently. A common mistake is to track a single system latency metric. That metric will always be dominated by the SLM path, will obscure degradation in the rule-based path, and will fail to surface emergency stop performance at all. Each contract needs its own test suite, its own monitoring, and its own release gate.
Safety Architecture: The Edge Changes Everything
Safety architecture for AI interfaces is a well-discussed topic. Edge deployment changes the nature of the problem in ways that are often underappreciated.
The standard cloud-era approach to AI safety is predominantly output filtering — the model generates something, the safety layer checks it, and the output is allowed or blocked. This is the right architecture when the AI is generating text that a human will read and then decide what to do with. It is the wrong architecture when the AI is directly connected to hardware that executes physical actions.
Edge AI interfaces that control physical systems require layered safety architecture with distinct responsibilities at each layer:
Input safety operates before any intent is classified. It validates that the input is physically possible (sensor readings within range), checks ASR confidence thresholds, and flags anomalies before the intent layer ever sees them.
Intent safety classifies every intent into a safety tier. The tiers determine what kind of confirmation is required, what operator mode is required, and whether the action can be executed at all in the current system state. A speed change requires a single tap to confirm. A GPS calibration requires a PIN. A factory reset requires double confirmation plus a PIN, in Technician mode only.
The SLM safety boundary deserves its own discussion. The SLM operates behind an explicit read-only boundary enforced at the tool execution layer. It has access to a named allowlist of read operations. The write namespace is not registered as callable — the SLM cannot attempt to write to hardware because the function does not exist in its callable scope. Every SLM output passes through a multi-stage validator that checks for false confirmation language, instruction injection, out-of-domain content, and language correctness before any output reaches the operator.
HAL safety adds a final layer: every write operation generates an ACK, reads back the written value, and verifies it against what was requested. A mismatch is never reported as success.
The key insight is that safety in a physical AI system is not a post-hoc filter — it is a structural property of how the system is built. The SLM cannot write to hardware not because of a policy that checks whether it is trying to — but because the write functions literally do not exist in the namespace it can call.
The SLM as a Reasoning Layer, Not an Interface Layer
A subtle but important architectural distinction: the SLM in this system is a reasoning component, not an interface component. It does not see the operator’s raw voice audio. It does not manage the session. It does not confirm actions. It does not generate responses that the operator acts on without review.
What the SLM does: it receives structured queries (the result of ASR, entity normalisation, and NLU classification), executes a sequence of read-only tool calls against on-device data stores, and produces a structured reasoning output that is then validated and formatted before being surfaced to the operator as an advisory.
The operator sees: “The most likely cause is progressive nozzle blockage. Flow has declined steadily at about 10 GPM per day for 7 days, while pressure has remained stable — which tells us the pump is not the issue.”
The operator does not see: the SLM’s chain of tool calls, the raw data it retrieved, its internal reasoning tokens, or any system state it accessed along the way.
This separation does several things. It keeps the SLM’s compute budget focused on reasoning quality rather than interface management. It means the SLM never has to handle the real-time latency constraints of the emergency stop or rule-based paths — those are handled by dedicated components that are structurally simpler and faster. And it ensures that SLM output can be validated by a dedicated output validator before it influences operator behaviour, without requiring the SLM itself to be designed as a safety-critical component.
Multilingual at the Boundary of the Model
Cloud AI multilingual support is predominantly a problem of model training: expose the model to enough multilingual data, and it handles multiple languages. Edge AI multilingual support is a resource allocation problem: every language you support has a memory and latency cost, and the budget is fixed.
The LoRA adapter approach resolves this by separating what must be large (the base multilingual model) from what must be per-language (the domain vocabulary adaptation). Each adapter is approximately 9MB — small enough to load all adapters into RAM simultaneously, so that language switching is instantaneous. The base model provides the multilingual substrate; the adapter provides the domain-specific steering for irrigation terminology, regional operator vocabulary, and local units of measure.
The harder problem is the SLM’s multilingual output. Template-based responses (the rule-based path) are fully authored in each language — quality controlled at the string level. SLM-generated reasoning is produced dynamically. Its quality in each language is a function of fine-tuning data availability, which is not uniform across languages.
This creates a quality tier problem that must be acknowledged in the architecture rather than papered over. Tier 1 languages (sufficient fine-tuning data for full reasoning quality) can be offered SLM reasoning without qualification. Tier 3 languages (limited fine-tuning data) require active output monitoring, a language coherence validator, and a graceful fallback to English with an explicit advisory to the operator. The fallback is never silent. The operator always knows when they are receiving a lower-quality response, and why.
The emergency keyword problem is a distinct challenge entirely. Emergency stop keywords must be matched phonemically across six languages, across regional accent variation, across high-noise environments, and with low false-positive and near-zero false-negative rates. This is not a language model problem — it is a signal processing problem. The architecture treats it as such, separating it completely from the NLU stack and giving it its own always-on thread and its own latency contract.
Session Design for Intermittent-Use Environments
Consumer AI interfaces are designed around sessions that begin with a user sitting down and end with them closing the app. The user is present and engaged for the duration. Field AI interfaces have a fundamentally different session pattern.
Operators interact with a panel for 30 seconds, then walk away for two hours to check on something in the field, then return and expect the system to remember where they were. They begin a configuration flow, get interrupted by a phone call mid-way through, come back the next morning, and expect the system to either resume or tell them clearly what was left incomplete. They ask a question, forget they asked it, and ask the same question again from a different angle.
This requires a session model built around checkpoint and resume rather than continuous presence. Every turn of a guided multi-step flow must be persisted atomically to flash before responding — a power failure mid-flow should leave no partial state applied to hardware. The operator who returns after an interruption should be offered a clear summary of where they were: not a log of everything that happened, but a human-readable statement of what was collected and what remains.
The confirmation architecture must also be built for interruption. A confirmation that was presented and never acknowledged should expire cleanly — auto-cancelled, never auto-confirmed. The principle is that hesitation should always resolve in the safe direction.
The Proactive Layer: From Reactive to Anticipatory
The most valuable capability a well-designed edge AI interface adds is not better answers to operator questions — it is the ability to surface conditions that the operator did not know to ask about.
A rule-based proactive monitor evaluates sensor history continuously in the background. When flow rate has declined 12 percent below its 7-day baseline, it fires an alert. When tire pressure on a tower has been declining at 3 PSI per hour for the past two hours, it fires an alert. The monitor uses no language model — it is threshold logic running against the on-device time-series store. It fires the same way for the same condition, always.
What the language model adds is the why. The alert tells the operator: “Flow rate is 12% below weekly average. Possible restriction.” The operator acknowledges and asks: “Why is the flow dropping?” The SLM reasoning path runs its tool calls, retrieves the 7-day flow trend, pressure trend, and fault history, and generates: “The decline is gradual and consistent — about 10 GPM per day. Pressure has stayed stable, which rules out the pump. Most likely cause is progressive nozzle blockage across a section of the system.”
The alert and the reasoning are architecturally separate. The alert is always deterministic, always rule-based, always fast. The reasoning is always probabilistic, always SLM-based, always invoked by the operator. Neither replaces the other. The alert ensures the operator notices the condition. The reasoning helps them understand it. These are different cognitive jobs that require different tools.
What Edge AI Interface Design Teaches About AI Interfaces in General
The constraints of edge deployment surface design principles that are, on reflection, valuable everywhere:
Separate reasoning from execution. The SLM reasons. The AEE executes. The HAL writes. Nothing spans all three. This separation keeps each component simpler, testable, and replaceable. Cloud AI systems that route reasoning and execution through the same model component are harder to make safe, harder to test, and harder to audit.
Design latency as a set of contracts, not a single metric. Different interaction types have different latency semantics. Mixing them into a single metric obscures performance problems and makes it impossible to reason clearly about safety.
Make safety structural, not behavioral. A system that cannot attempt certain actions is safer than a system that attempts them and then checks whether it should have. The SLM’s inability to write to hardware is a structural property, not a runtime check.
Acknowledge quality variance honestly. A system that produces different quality outputs in different languages should say so, surface a fallback, and let the operator make an informed choice. Hiding quality variance is not operator-friendly — it is operator-deceiving.
The legacy interface is not the enemy. Field operators with years of experience using a button-based menu are not wrong. They have invested in a skill that works. The AI interface’s job is to be faster for frequent operations while leaving their existing skill intact. A well-designed coexistence model — where the hardware menu button always does exactly what it always did — converts skeptics faster than any amount of AI capability.
The Arc This Points To
Edge AI is not a niche market. It is the next phase of AI deployment. The patterns that cloud AI normalised — stateless sessions, unlimited compute, network-dependent inference, single-model architectures — are already being stress-tested as AI moves into vehicles, surgical robotics, energy infrastructure, and industrial control systems.
The two-path execution model, the layered safety architecture, the read-only SLM boundary, the three independent latency contracts, the checkpoint-and-resume session model — none of these are irrigation-specific solutions. They are solutions to problems that arise whenever AI is deployed at the boundary between digital intelligence and physical consequence.
The discipline that edge constraints impose is not a limitation on what AI interfaces can do. It is a clarification of what they should do, and why.