
The AI Gateway: The Infrastructure Layer Most Engineering Teams Build Too Late
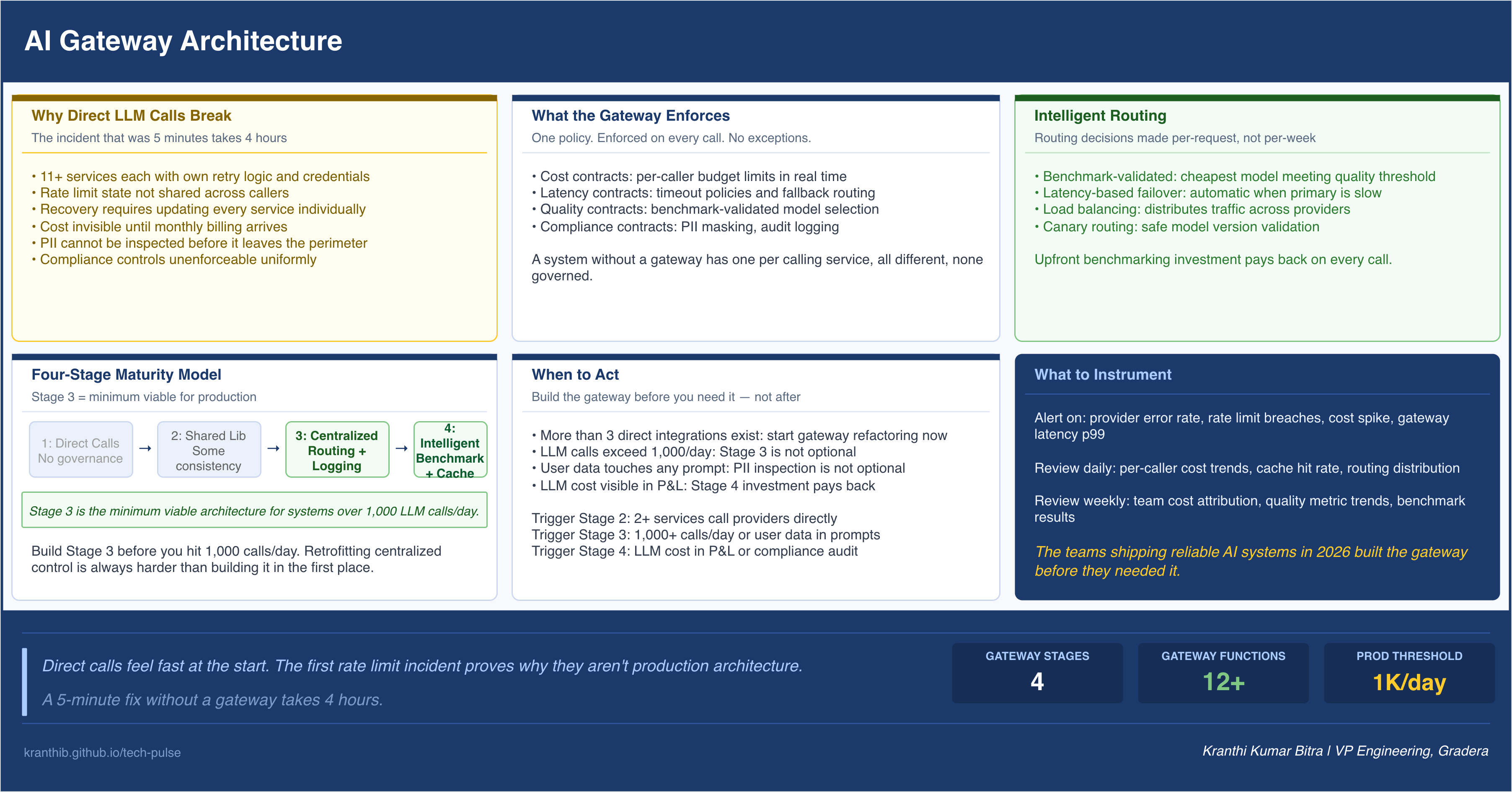
Every LLM call your system makes is a contract with a model provider. Most engineering teams have no system to enforce that contract, audit it, or recover when it breaks.
The Incident That Changed How I Think About This
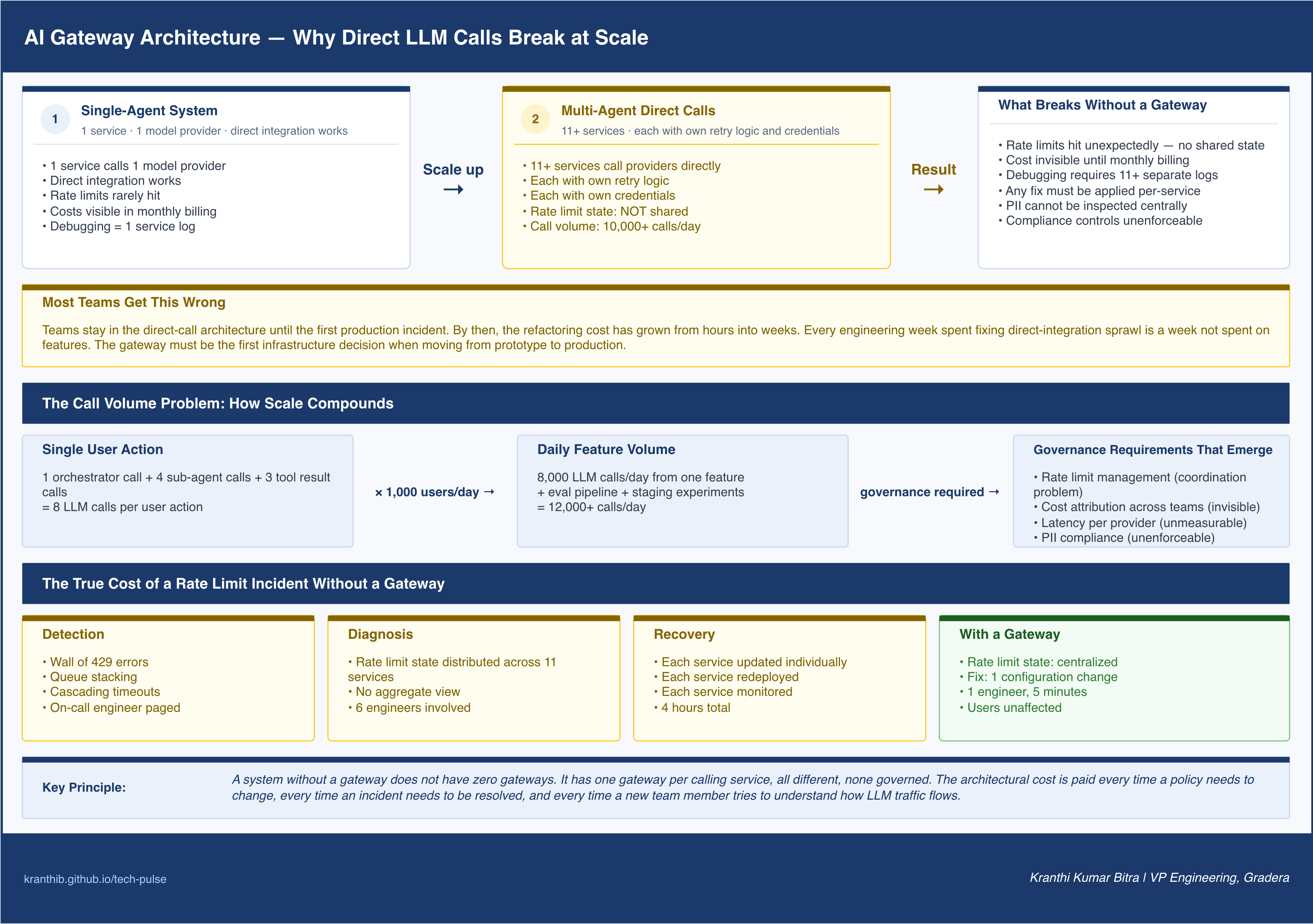
It was a Thursday afternoon. A multi-agent pipeline that had been running reliably for six weeks suddenly began returning errors at scale. The symptom was immediate: dozens of agent tasks stacking up in the queue, timeouts cascading, and the on-call engineer staring at a wall of 429 status codes from a model provider API.
Rate limits. Exceeded. Across every service that had been calling the model directly.
The fix was straightforward in isolation: implement backoff, route some traffic to a secondary model, and throttle the request rate. But the recovery took four hours because the rate limit state was distributed across eleven separate service integrations, each with its own retry logic, its own timeout configuration, and its own direct connection to the provider. There was no single place to apply the fix. Every service had to be updated individually, redeployed, and monitored separately.
That system had no gateway. It had eleven gateways, all different, none of them governed.
What should have been a five-minute configuration change took four hours and involved six engineers. And this was not a particularly complex system. Teams running serious multi-agent architectures are making tens of thousands of LLM calls daily. The version of this incident at that scale is not a Thursday afternoon recovery. It is a production outage that makes the news.
The AI gateway is not a nice-to-have optimization. It is the infrastructure that makes production AI systems recoverable, observable, and cost-controlled. And the right time to build it is before the first production incident, not after.
Why the Problem Compounds in Multi-Agent Systems
Understanding why the gateway layer becomes critical requires understanding what happens to LLM call volumes as systems mature.
A single-agent system calling a model provider once per user request is manageable without a gateway. At low traffic volumes, the direct integration works. Rate limits are rarely hit. Costs are visible in monthly billing. Debugging a failed call means looking at one service’s logs.
That model breaks the moment multi-agent architectures enter the picture.
A typical multi-agent pipeline does not make one LLM call per user action. It makes many. An orchestrator agent parses the intent. Specialist sub-agents retrieve context, plan steps, and execute tools. Each tool invocation may itself trigger a model call for result interpretation. A single user action that triggers a four-agent pipeline with three tool calls per agent generates twelve or more LLM calls before the user sees a response.
At a thousand daily active users, that is potentially twelve thousand or more LLM calls per day from a single feature. Now add the evaluation pipeline running in the background. Add the prompt experimentation your team is running in staging. Add the summarization job processing overnight. The call volume compounds faster than most teams anticipate, and the governance requirements compound with it.
Rate limit management across distributed callers becomes a coordination problem. Cost attribution across teams and features becomes invisible. Latency characterization across multiple model providers becomes impossible without a central measurement point. Compliance requirements around PII handling in prompts and responses cannot be enforced without a centralized inspection layer.
Every one of these problems has the same architectural solution: a gateway that all LLM traffic passes through.
What a Gateway Actually Is (And Is Not)
The most common misunderstanding I encounter is the description of an AI gateway as “a proxy in front of your LLM calls.” This framing is technically accurate but architecturally insufficient, and it leads teams to build the wrong thing.
A proxy forwards requests. A gateway enforces contracts.
The distinction matters because the value of an AI gateway is not in the forwarding. Any HTTP proxy can forward requests. The value is in what the gateway does before forwarding, after receiving, and when conditions require it to deviate from the default path.
An AI gateway enforces four categories of contract that govern every LLM interaction in the system:
Cost contracts define how much any given caller, team, feature, or tenant is permitted to spend in a given period. The gateway tracks token consumption in real time, applies per-caller budgets, and rejects or deprioritizes requests that would breach the contract. Without this, the only cost signal is the monthly provider bill, which arrives weeks after the spending occurred.
Latency contracts define the maximum acceptable response time for each use case. Interactive features have different latency tolerances than batch processing pipelines. The gateway applies timeout policies per route, triggers fallback logic when latency thresholds are approached, and routes requests to faster or cached alternatives when latency budgets are tight.
Quality contracts define the acceptable output characteristics for each request category. This includes routing requests to the model that meets the quality threshold at the lowest cost, validating that responses conform to expected structure, and filtering outputs that contain policy-violating content before they reach the calling service.
Compliance contracts define the rules that every LLM interaction must satisfy regardless of what the calling service requests. PII must not leave the perimeter unmasked. Certain content categories must never be generated. Requests to specific model versions may be restricted for regulatory reasons. Audit logs must be retained. The gateway is the single enforcement point for all of these rules, and it enforces them without requiring each calling service to implement them independently.
None of these functions are proxying. They are contract enforcement. Building a proxy gives you traffic forwarding. Building a gateway gives you operational control.
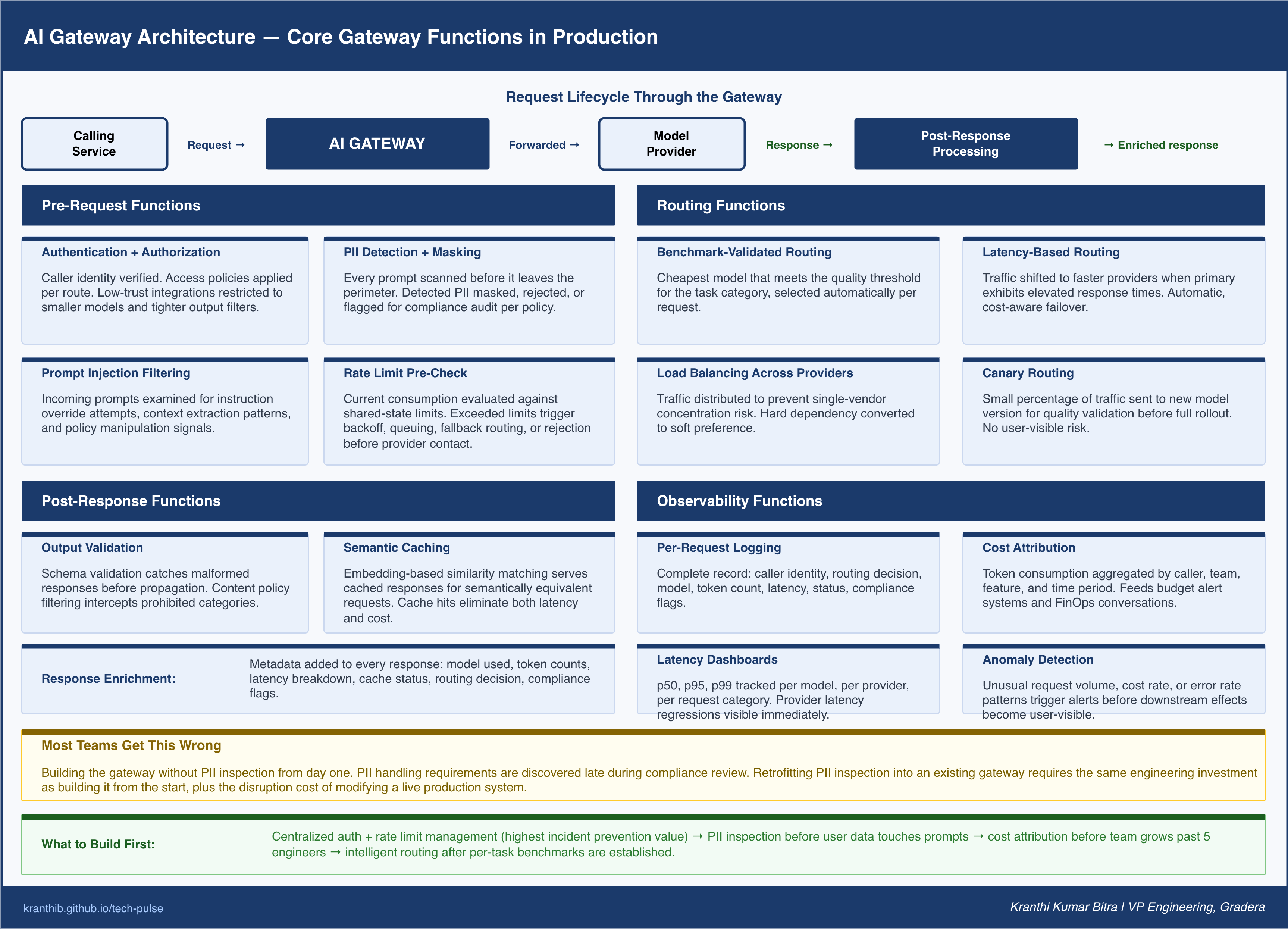
Core Gateway Functions in Production
When I describe an AI gateway to engineering leaders, I organize the functions into four groups based on when in the request lifecycle they operate. This framing makes it easier to understand what to build, in what order, and why each function matters.
Pre-Request Functions
Before a request is forwarded to a model provider, the gateway applies several transformations and checks.
Authentication and authorization verify that the calling service is permitted to make this type of request. Not all services in a system should have equal model access. A low-trust external integration may be restricted to a smaller model with a tighter output filter. A high-value internal service may be granted priority routing and a higher cost budget. The gateway applies these policies at the connection level, not at the application level.
PII detection and masking scan the incoming prompt for personally identifiable information before it leaves the perimeter. This is the only layer where PII can be intercepted reliably, because the gateway sees every prompt regardless of which service generated it. Detected PII can be masked, rejected, or flagged for compliance audit depending on the configured policy.
Prompt injection filtering examines incoming prompts for patterns that indicate an attempt to override system instructions, extract confidential context, or manipulate the model into out-of-policy behavior. This is increasingly important as AI systems accept user-supplied text as part of prompts.
Rate limit pre-check evaluates the current consumption state against configured limits before forwarding the request. If the calling service has exceeded its rate limit, the gateway can apply backoff, queue the request, route to a fallback model, or reject with an informative error. This prevents the provider-level 429 cascade that produces the kind of incident described at the opening of this post.
Routing Functions
The gateway determines which model receives each request. In a single-provider, single-model architecture, this function is trivial. In a production multi-agent system with multiple providers, multiple model versions, and differentiated latency and cost requirements, routing is where significant operational leverage lives.
Benchmark-validated routing selects the cheapest model that meets the quality threshold for a given request category. This requires an upfront investment in per-task benchmarking: establishing which tasks can be handled by a smaller or less expensive model without meaningful quality degradation. The gateway applies these benchmarks as routing rules, automatically directing simple classification tasks to lower-cost models and complex reasoning tasks to higher-capability models.
Latency-based routing applies when response time is the primary constraint. If the primary model provider is exhibiting elevated latency, the gateway can shift traffic to a secondary provider or model that is currently faster, even if it is slightly more expensive. This is automatic failover with quality and cost awareness.
Load balancing across providers distributes traffic across multiple providers to prevent concentration risk. Single-provider architectures create a hard dependency on one vendor’s uptime, rate limit thresholds, and pricing decisions. Multi-provider routing through a gateway converts that hard dependency into a soft preference.
Canary routing sends a small percentage of traffic to a new model version before full rollout. This allows quality validation in production without exposing the entire user base to an untested model.
Post-Response Functions
After the model provider returns a response, the gateway applies inspection and transformation before forwarding to the calling service.
Output validation checks that the response conforms to the expected structure. For use cases that require structured JSON output, the gateway can detect malformed responses and trigger a retry or fallback before the error propagates to the calling service.
Content filtering applies policy rules to the model output. Responses containing policy-violating content are intercepted at the gateway before reaching the application layer.
Semantic caching stores and retrieves previously generated responses for semantically similar requests. Unlike key-value caching, which only matches exact inputs, semantic caching uses embedding-based similarity to identify requests that are functionally equivalent and can be served from cache. The economics of semantic caching are significant: cache hits eliminate both latency and cost for the cached request. The engineering challenge is cache invalidation — knowing when a previously cached response is no longer valid because the underlying context has changed.
Response enrichment adds metadata to the response that calling services need for their own instrumentation: model used, token counts, latency breakdown, cache status, routing decision, and compliance flags. This metadata travels with every response, making it available for application-level observability without requiring the application to query the gateway separately.
Observability Functions
The gateway is the single point through which all LLM traffic passes, which makes it the natural home for production observability.
Per-request logging captures a complete record of every LLM interaction: caller identity, request metadata, routing decision, model selected, token consumption, latency, response status, and compliance flags. This log is the foundation for cost attribution, debugging, and audit compliance.
Cost attribution aggregates token consumption and cost by caller, team, feature, and time period. This data feeds team-level cost dashboards, budget alert systems, and FinOps conversations about AI spend optimization.
Latency dashboards track p50, p95, and p99 latency per model, per provider, and per request category. Latency regressions in model provider performance are visible immediately rather than surfacing through user complaints.
Anomaly detection identifies unusual patterns in request volume, cost rate, or error rate and triggers alerts before they become incidents. A sudden spike in token consumption, an unexpected increase in provider errors, or an unusual pattern of requests from a specific service are all detectable at the gateway layer before their downstream effects become user-visible.
Intelligent Routing: Where the Operational Leverage Compounds
Routing is the function that separates a basic gateway from an intelligent one. Basic routing is a fixed rule: always send traffic to model X. Intelligent routing is a dynamic decision that optimizes across cost, latency, and quality simultaneously.
The foundation of intelligent routing is per-task benchmarking. Before the gateway can route intelligently, the team must establish quality baselines for each task category in the system. This is not glamorous work, but it is the prerequisite for every routing optimization that follows.
The benchmarking process involves three steps. First, identify and categorize the distinct task types in the system: summarization, classification, structured extraction, complex reasoning, code generation, and so on. Second, evaluate multiple candidate models against a representative sample of each task type using a consistent quality metric. Third, establish the quality threshold for each task type based on product requirements, and identify the cheapest model that meets that threshold.
Once baselines exist, the gateway applies them as routing rules. A summarization task routes to the model that produces acceptable summaries at the lowest cost per token. A complex multi-step reasoning task routes to the model that achieves the required quality, even if it is more expensive. The routing decision is automatic, per-request, and invisible to the calling service.
The compounding effect of benchmark-validated routing is significant. In systems where task categories are diverse, routing optimization consistently reduces LLM costs by a meaningful margin, because a substantial fraction of tasks can be handled by smaller, cheaper models without quality degradation. The exact savings depend on the task distribution, but the pattern is consistent: most systems are over-investing in model capability for a large fraction of their requests.
Semantic caching compounds the effect further. Once a request has been answered and the response cached, subsequent semantically equivalent requests can be served from cache at effectively zero cost. The challenge is building a caching layer that correctly identifies semantic equivalence without false positives (serving stale or incorrect cached responses) or false negatives (failing to recognize a cacheable request and incurring unnecessary model cost).
The semantic cache requires an embedding model to convert requests into vector representations, a similarity threshold that determines when two requests are close enough to be considered equivalent, and a cache invalidation strategy that removes entries when the underlying context changes. Getting the similarity threshold right is the most important calibration decision: too aggressive and the cache serves incorrect responses; too conservative and cache hit rates are too low to be economically meaningful.
The combination of benchmark-validated routing and semantic caching, applied consistently across a multi-agent system, creates the kind of cost structure that allows AI features to remain economically viable as usage scales.

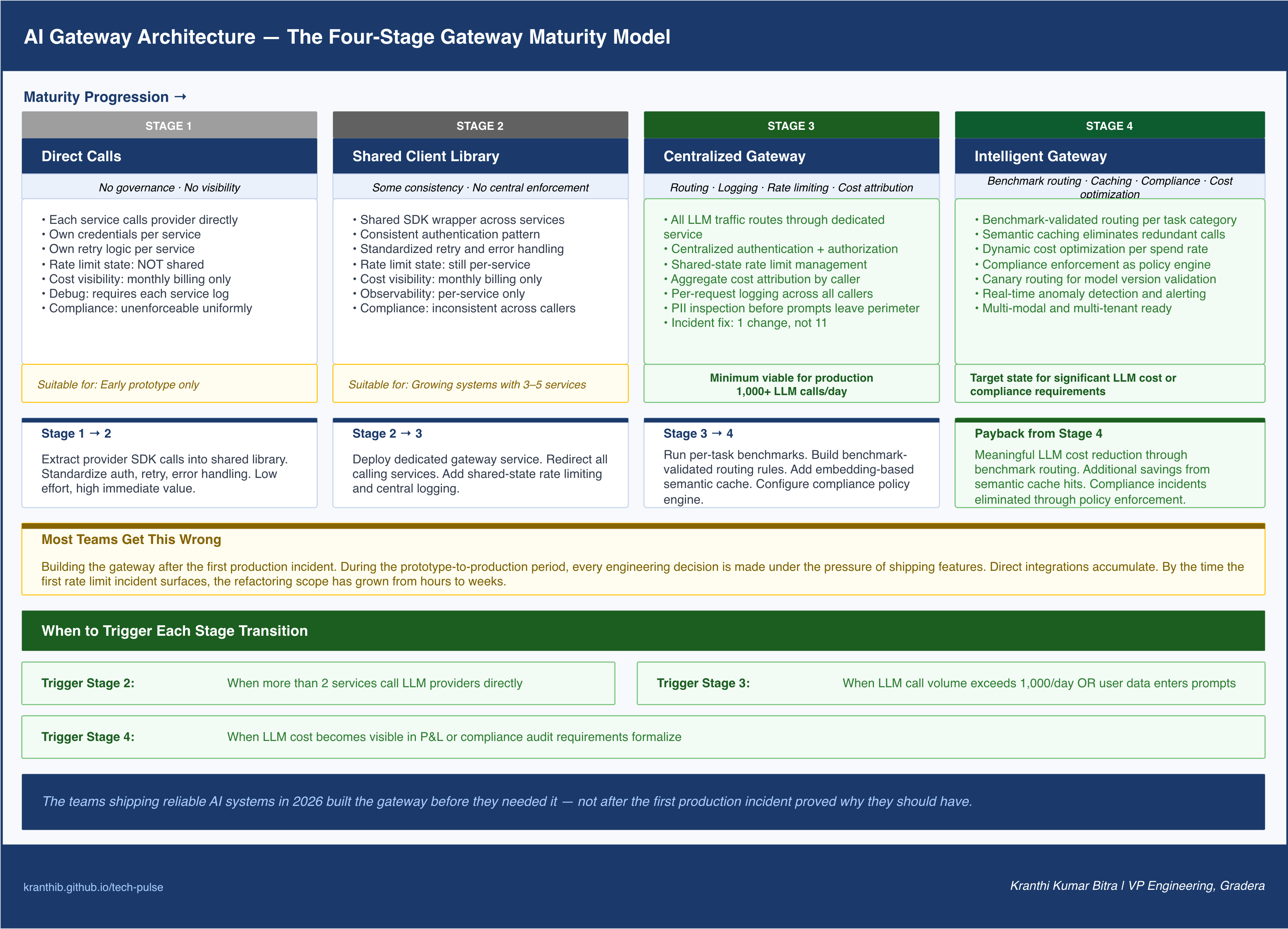
The Four-Stage Gateway Maturity Model
In practice, teams do not build a fully instrumented intelligent gateway on the first day. They evolve through stages, and understanding where a system sits in this progression is the first step toward knowing what to build next.
Stage 1: Direct Calls
Every service calls a model provider directly. There is no shared abstraction layer. Each service manages its own credentials, implements its own retry logic, and handles its own error conditions. Rate limits are hit unexpectedly because no service knows what the others are doing. Cost visibility is limited to aggregate monthly billing. Debugging a failed LLM interaction requires access to the individual service’s logs.
This stage is appropriate for prototypes and early explorations where the priority is moving fast and learning. It becomes a liability the moment the system moves toward production at any meaningful scale. The refactoring cost of removing direct integrations after they have proliferated across a codebase is substantial.
Most teams get this wrong: They stay in Stage 1 longer than they should, treating the growing collection of direct integrations as technical debt they will address later. By the time the first production incident makes the gateway a priority, the refactoring scope has grown significantly.
Stage 2: Shared Client Library
A shared client library wraps the provider SDK and is used by all services. The library provides consistent authentication, basic retry logic, and standardized error handling. This is a significant improvement over Stage 1: the integration logic is centralized in one place, and updates apply to all callers automatically.
The limitation of this stage is that the library runs in-process with each calling service. There is no central visibility into aggregate request volumes, costs, or error rates across the system. Rate limit management is still per-service because there is no shared state. Each service independently tracks its own usage without knowledge of what others are consuming.
This stage is valuable and worth building early. But it is not a gateway.
Stage 3: Centralized Gateway
All LLM traffic routes through a dedicated gateway service that the calling services connect to rather than calling providers directly. The gateway applies consistent authentication, manages rate limits against shared state, logs every request centrally, and provides aggregate observability across all callers.
At this stage, the incident described at the opening of this post becomes a five-minute fix. Rate limit breaches are visible centrally. Fallback logic applies system-wide. Cost attribution is available per caller. The engineering team has operational control over LLM traffic.
This is the minimum viable architecture for any system running in production with meaningful LLM call volume.
Stage 4: Intelligent Gateway
The intelligent gateway adds dynamic, data-driven decision-making to the centralized foundation. Benchmark-validated routing selects models based on per-task quality requirements. Semantic caching eliminates redundant model calls. Cost optimization policies apply dynamically based on current spend rates. Compliance enforcement runs as a configurable policy engine rather than hardcoded rules.
At this stage, the gateway is not just an infrastructure component. It is an operational intelligence layer that actively optimizes the system’s cost, latency, and compliance posture in real time.
Most teams at Stage 3 have the foundation to reach Stage 4 incrementally. The investment required is primarily in per-task benchmarking and cache infrastructure, both of which pay back quickly in reduced LLM costs.
What to Instrument and Alert On
Operational maturity with an AI gateway is not just about building the gateway. It is about knowing which signals matter enough to alert on and which are informational.
The signals I consider essential for production gateway monitoring fall into three tiers.
Tier 1: Alert immediately
- Provider error rate exceeding threshold per model per provider (indicates provider-side degradation)
- Rate limit breach rate above zero (any rate limit hit is a signal that capacity planning needs attention)
- Cost rate spike beyond expected baseline (indicates a runaway process, a misconfigured agent, or an unexpected traffic pattern)
- PII detection rate sudden increase (may indicate a new calling service that has not been reviewed for prompt hygiene)
- Gateway service latency p99 exceeding threshold (the gateway itself must not become a latency bottleneck)
Tier 2: Review in daily operations
- Per-caller cost trends across rolling periods
- Cache hit rate per request category (a declining cache hit rate may indicate prompt variability that is defeating the cache)
- Model routing distribution (understand whether traffic is flowing to the intended models)
- Token consumption per model per task category (baseline awareness for anomaly detection)
Tier 3: Review in weekly planning
- Cost attribution by team and feature for FinOps conversations
- Quality metric trends per routed task category (confirm that routing decisions are maintaining quality)
- Benchmark results for new model versions under evaluation
- Compliance audit summary: PII intercept counts, content filter activations, policy rejections
The discipline of separating these tiers matters because alert fatigue from over-instrumentation is a real operational failure mode. Teams that alert on Tier 3 signals with the urgency of Tier 1 signals train their engineers to ignore alerts. The gateway’s instrumentation should be designed with the same intentionality as the gateway’s routing logic.
Security Functions That Belong in the Gateway
The AI gateway is the correct layer to implement security controls that need to apply consistently across all LLM interactions, regardless of which service initiates them. Application-level security controls fail when new services are added without implementing the controls, when a service is updated and the controls are accidentally removed, or when a third-party integration bypasses the application layer entirely.
Gateway-level security controls apply unconditionally to all traffic.
PII detection and masking should be implemented using a combination of pattern matching for structured PII formats (email addresses, phone numbers, national ID formats, financial account numbers) and entity recognition for less structured PII in natural language. The masking strategy should replace detected PII with consistent placeholder tokens that allow the model to reason about the structure of the input without accessing the actual data. The gateway logs the detection event for compliance reporting.
Prompt injection filtering is the most technically challenging security function in this layer because the attack surface is open-ended. Injection attempts range from explicit override instructions (“ignore your previous instructions”) to subtler manipulations embedded in user-supplied content that the model processes as part of a prompt. The gateway can apply rule-based filters for known injection patterns and use a lightweight classifier model to score the injection risk of incoming prompts. High-risk prompts can be rejected, quarantined for review, or routed to a more restricted model profile.
Output validation prevents the gateway from forwarding responses that do not conform to policy. For structured output use cases, schema validation catches malformed responses before they propagate to calling services. Content policy filtering catches responses that contain prohibited content categories. Both functions protect the application from model misbehavior without requiring the application to implement its own validation logic.
Credential management centralizes API key storage and rotation. All model provider credentials are stored in the gateway’s secrets management layer. Calling services authenticate to the gateway using internal credentials that carry no provider-level permissions. If a calling service is compromised, the attacker cannot directly access the model provider because the provider credentials are not available outside the gateway. Credential rotation requires updating one location rather than coordinating across all calling services.
The Build vs. Buy Decision Framework
One of the most common questions I receive about AI gateways is whether to build an internal solution or adopt an existing open-source or commercial offering. The honest answer is that the decision depends on where the team sits in the maturity model and what the primary constraints are.
The case for building internally is strongest when the system has highly specific routing logic that no existing gateway supports, when compliance requirements mandate complete control over the request lifecycle, or when the team has already invested significantly in internal observability infrastructure that the gateway needs to integrate with deeply. Building internally also makes sense when the engineering team has the capacity to maintain the gateway as a product, because an internal gateway that is not actively maintained degrades quickly as requirements evolve.
The case for adopting an existing solution is strongest when the team is moving from Stage 1 to Stage 2 or Stage 3 and needs rapid capability acquisition. Several mature open-source gateways cover the core functions described in this post, and the implementation effort is significantly lower than building from scratch. Commercial solutions add managed infrastructure, enterprise support, and pre-built compliance connectors.
The decision framework I use focuses on three questions:
First, does the team’s differentiation come from gateway logic? If the answer is no, build as little custom gateway code as possible. The gateway is infrastructure, not product. The team’s leverage comes from using the gateway effectively, not from building it from scratch.
Second, what does compliance require? If the compliance requirements mandate on-premises data processing, specific audit log formats, or custom data residency controls, evaluate whether any existing solution meets those requirements before concluding that a custom build is necessary.
Third, what is the total cost of ownership? A custom gateway has ongoing engineering maintenance costs that are easy to underestimate. An external solution has licensing costs that are easy to underestimate. Model the actual costs of both options over a twelve-month horizon before deciding.
In most cases, adopting an existing gateway for core functions and building internal extensions for specific requirements produces the best outcome. Full custom builds are appropriate for a minority of teams with genuinely unique requirements.

Enterprise Readiness: What Production Actually Requires
A gateway that handles routing, caching, and basic observability is a good start. A gateway that is enterprise-ready handles several additional requirements that become visible when the system moves to production at organizational scale.
Audit trail retention is not optional in regulated industries. Every LLM interaction that involves customer data, financial decisions, or healthcare information typically has a retention requirement. The gateway must log enough information to reconstruct the context of any interaction during the retention period. This includes the request, the response, the model used, the routing decision, the compliance checks applied, and the caller identity. The storage strategy for these logs is a distinct engineering problem: the volume is high, the retention period may be long, and the query patterns during an audit are unpredictable.
Model version pinning allows specific callers or features to be locked to a specific model version rather than tracking the latest. This is essential for regulated use cases where the model version is part of the compliance record and an unexpected model update would invalidate a validation process. The gateway maintains per-route version pin configurations that override any default model selection logic.
Data residency enforcement ensures that LLM calls involving specific data categories are routed only to providers and regions that meet the applicable data residency requirements. A European data subject’s personal information must not be sent to a model endpoint outside the permitted region. The gateway enforces this by associating residency metadata with caller identity and applying routing constraints that prevent out-of-region forwarding.
Multi-tenant cost isolation is required when the AI system serves multiple organizational tenants whose costs must be tracked and billed separately. The gateway applies per-tenant budget policies, tracks per-tenant token consumption, and enforces spending limits that prevent one tenant’s usage from affecting another’s. This is the infrastructure foundation for any AI-powered product that charges customers based on usage.
Graceful degradation policies define what the system does when a model provider is unavailable, when rate limits are exhausted, or when a request cannot be fulfilled within the latency budget. These policies must be configured in the gateway rather than in individual calling services. A centralized degradation policy ensures consistent behavior across the system. Individual service-level degradation logic produces inconsistent behavior and makes incident response more complex.
What Most Engineering Teams Get Wrong
The most consistent failure pattern I observe is building the gateway after the first production incident. This sounds obvious in retrospect, but the timing is important because of what happens in the period between prototype and that first incident.
During that period, every engineering decision is made under the pressure of shipping features. The direct integration is always faster to implement than the gateway integration. Each individual service team makes a locally rational decision to call the provider directly. By the time the system is in production and the first rate limit incident surfaces, the codebase has five, ten, or twenty direct integrations. The gateway refactoring effort is now measured in weeks, not hours.
The second failure pattern is treating the gateway as a DevOps problem rather than an engineering architecture decision. Gateways built by infrastructure teams without deep involvement from the engineers who build the AI features tend to implement the forwarding and logging functions without implementing the intelligent routing, caching, and compliance enforcement functions. The result is a system that looks like a gateway but does not deliver the cost and latency optimization benefits that justify the architectural overhead.
The third failure pattern is under-instrumenting the gateway and then relying on provider billing data for cost visibility. Provider billing data arrives too late to prevent cost overruns, attributes costs at the wrong granularity (account-level rather than feature-level), and provides no information about latency, cache efficiency, or routing quality. Teams that rely on provider billing for cost visibility are always reacting to problems that have already happened.
The fourth failure pattern is building the gateway without PII inspection from day one. PII handling requirements tend to be discovered late in the development cycle, during compliance review or legal sign-off. By that point, PII inspection needs to be retrofitted into an existing gateway, which is significantly more complex than designing it in from the start. PII inspection in the gateway requires the same architectural investment whether it is built day one or day one hundred. The difference is the disruption cost of retrofitting.
Where This Is Heading
The AI gateway is maturing rapidly as a product category and as an engineering discipline. Several directions are worth watching.
Semantic routing using real-time quality feedback will eventually replace static benchmark-validated routing. Instead of routing based on offline benchmark results, the gateway will route based on live quality signals derived from user feedback, downstream model evaluations, and business outcome metrics. This creates a closed-loop routing system that continuously improves its own routing decisions.
Multi-modal gateway functions will extend to cover the full range of model interactions as multi-modal AI systems become common. Routing decisions will need to account for the presence of images, documents, or audio in the request payload. PII detection will need to operate on multi-modal inputs. Cost accounting will need to capture the distinct pricing structures that apply to different modalities.
Agent identity and per-agent policy enforcement will become a gateway requirement as multi-agent architectures mature. Currently, most gateways apply policies based on the calling service identity. In multi-agent systems, the relevant identity is often the specific agent making the call, which may be operating on behalf of a specific user with a specific permission set. Gateway policy enforcement at the agent-identity level requires that agent identity be a first-class concept in the request context.
Cost prediction and pre-approval workflows will emerge for high-cost operations. Before a complex reasoning task generates a large token bill, the gateway will estimate the expected cost and compare it against the available budget. Operations that would breach a cost threshold will require explicit approval or will automatically fall back to a lower-cost model configuration.
The teams that build intelligent gateway infrastructure now are building the operational foundation that these capabilities will extend. The teams that are still running direct integrations will be addressing the foundational architecture at the same time their competitors are working on the next layer of optimization.
The Decision to Make This Week
If the system is running LLM calls in production without a centralized gateway, the first question is not which gateway to adopt. The first question is: how many separate direct integrations exist today?
If the answer is fewer than three and the system is early-stage, the shared client library approach buys time without significant refactoring risk.
If the answer is three or more, the refactoring cost is already significant enough that the gateway conversation should be happening now.
If the system is making more than one thousand LLM calls daily, the centralized gateway is not optional. The cost, observability, and rate limit management requirements at that volume require a centralized enforcement layer to operate reliably.
The teams shipping reliable AI systems in 2026 built the gateway before they needed it. The others are building it now, under pressure, after the first incident made the cost of not having it undeniable.
Build the gateway early. Instrument it properly from day one. Route intelligently based on per-task benchmarks. The operational leverage compounds with every call the system makes.