
Building Intelligent AI Agents: The Architecture of Memory That Actually Works
The biggest lie in the AI agent ecosystem right now is that a well-crafted prompt is all you need to build a production-grade assistant. I have spent considerable time designing and deploying agent architectures, and I can tell you with certainty: the difference between a demo-worthy chatbot and an enterprise-grade AI agent comes down to one capability – memory.
Not the vague, hand-wavy notion of “the model remembers things.” I am talking about a rigorous, multi-layered engineering discipline that determines how an agent acquires knowledge, organizes it for rapid retrieval, and evolves that knowledge over time. This is the discipline I now refer to as Context Engineering, and it is the single most important architectural decision you will make when building stateful AI systems.
In this post, I want to walk through the mental models and architectural patterns I have developed while working on agent memory systems. I will cover the full lifecycle – from the fundamentals of session management and long-term memory, through the emerging paradigm of graph-based memory architectures, to the production considerations that separate toy projects from real systems.
The Problem: LLMs Are Born Stateless
Here is the fundamental challenge every agent builder must confront: Large Language Models are inherently stateless. Outside of their training data, their reasoning and awareness are confined entirely to the information present within the context window of a single API call. Every time you make a request, the model starts from a blank slate.
This means that for every single conversational turn, the agent framework must dynamically assemble and manage the entire informational payload the model needs to reason correctly. This includes operating instructions, evidential data, conversation history, user preferences, and tool definitions. This dynamic assembly process is what I call Context Engineering.

Think of Context Engineering as the mise en place for an agent – the crucial preparation step where a chef gathers and arranges all their ingredients before cooking. If you only hand the chef a recipe (the prompt), they might produce a passable meal with whatever random ingredients they find. But if you first ensure they have all the right, high-quality ingredients, specialized tools, and a clear understanding of the presentation, they can reliably produce an excellent, customized result. The goal is to ensure the model has no more and no less than the most relevant information to complete its task.
The entire practice of Context Engineering revolves around two core architectural components: Sessions and Memory. Understanding their distinct roles and their symbiotic relationship is the foundation of building any intelligent agent.
Part I: Sessions – The Immediate Workspace
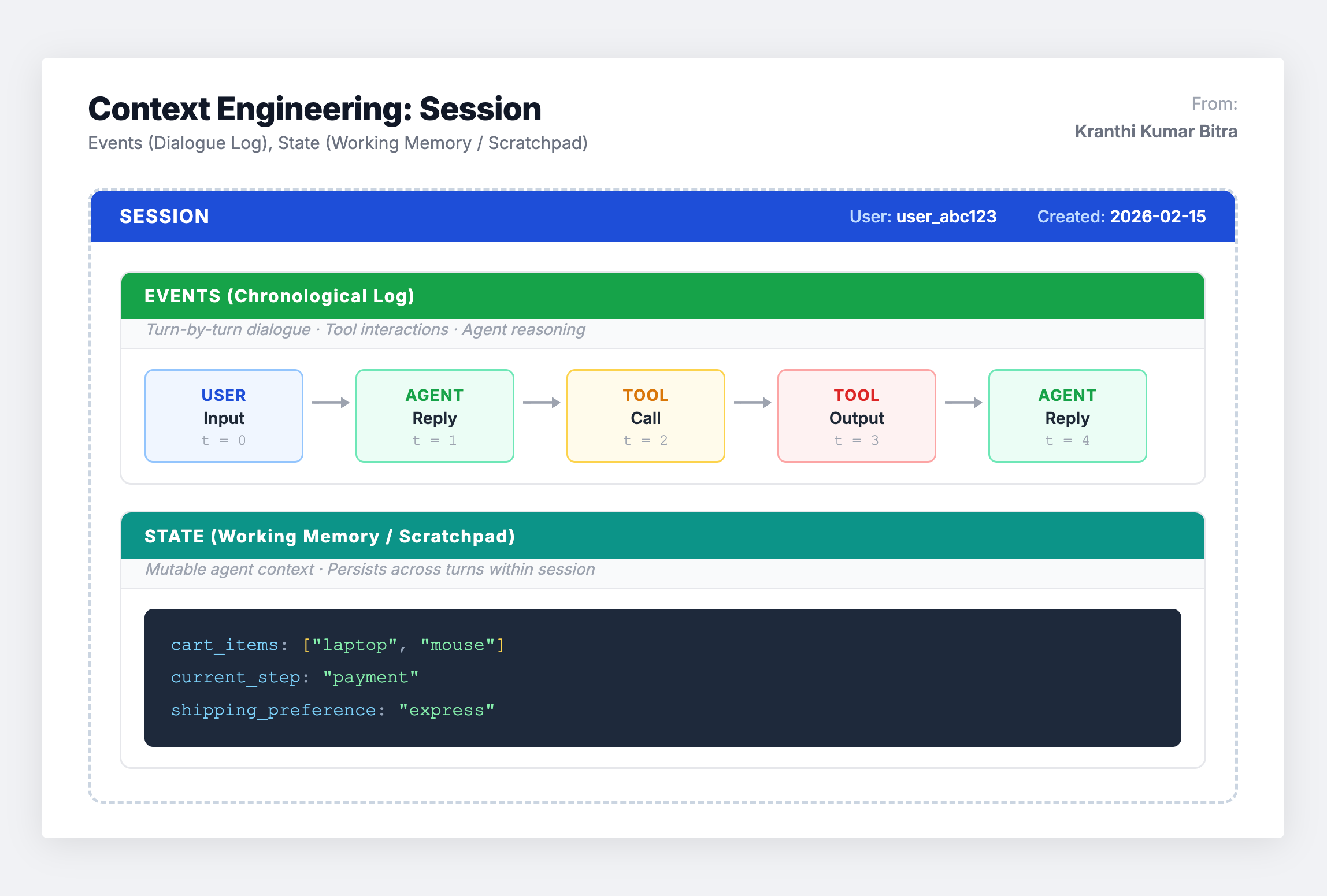
A session is the container for a single, continuous conversation between a user and an agent. It encapsulates the immediate dialogue history and working memory for that specific interaction. Every session is self-contained and tied to a specific user, functioning as a distinct, disconnected log of a particular exchange.
I find the workbench analogy most useful here. A session is the desk you are using for a specific project. While you are working, it is covered in all the necessary tools, notes, and reference materials. Everything is immediately accessible but also temporary and specific to the task at hand.
What Lives Inside a Session
Every session contains two fundamental components:
Events are the chronological building blocks of the conversation. These include user inputs (text, audio, images), agent responses, tool call requests made by the agent, and the data returned from those tool calls. Together, they form the sequential record of everything that happened.
State is the structured working memory or scratchpad. This holds temporary, structured data relevant to the current conversation – like items in a shopping cart, the current step in a multi-step workflow, or intermediate calculation results. As the conversation progresses, the agent appends new events and may mutate this state based on its internal logic.
The Long-Context Trap
Here is where most teams run into trouble. In theory, modern models with large context windows can handle extensive conversation transcripts. In practice, as context grows, three things happen simultaneously: cost increases (you are paying per token), latency rises (longer prompts take longer to process), and the model suffers from what I call context rot – a measurable degradation in the model’s ability to attend to critical information as the surrounding context expands.
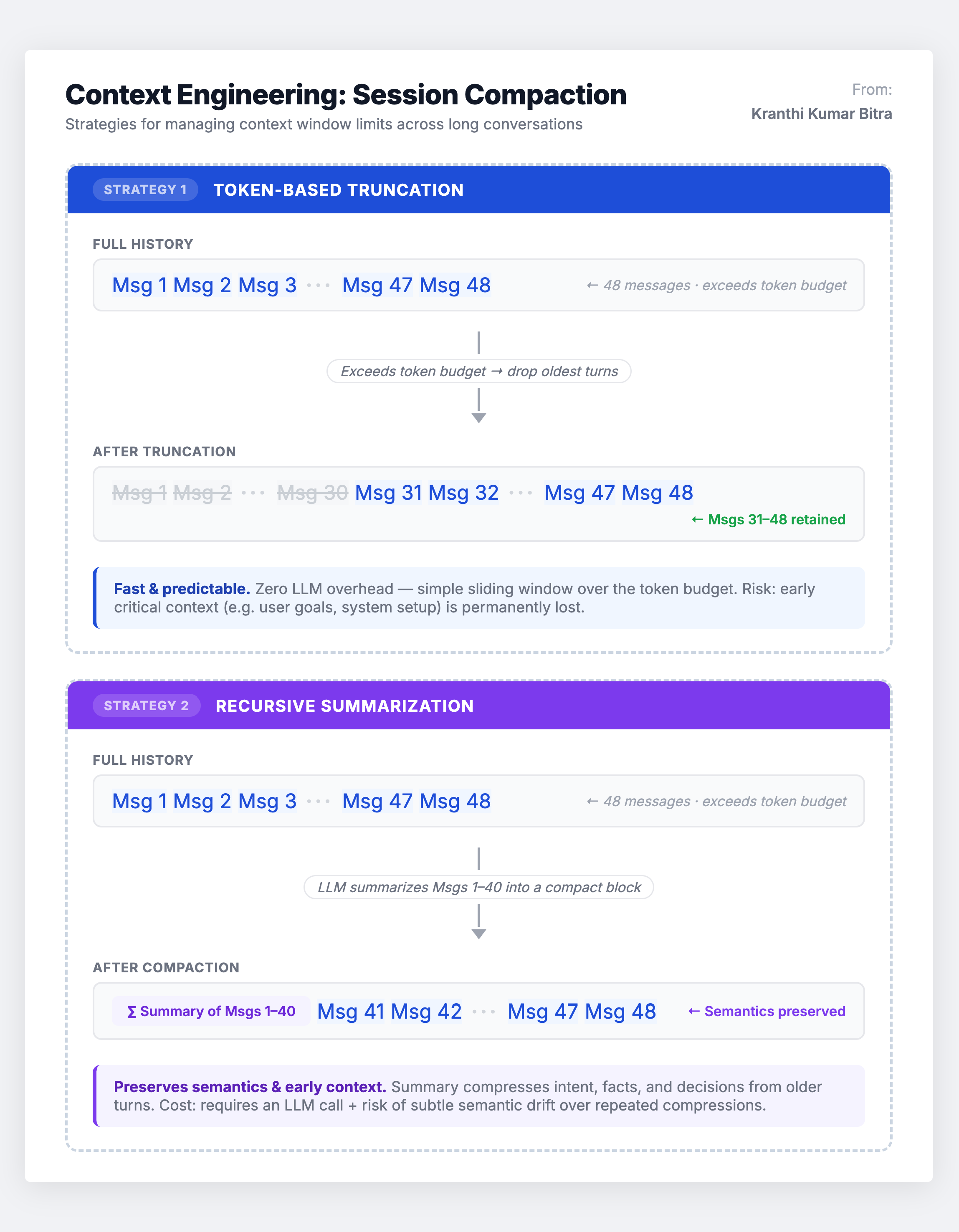
Context Engineering addresses this directly through session compaction strategies. The two primary approaches I have worked with are:
Token-based truncation is the simplest method. You set a maximum token budget and, when the conversation exceeds it, you prune the oldest events. It is fast and predictable, but you risk losing critical early context – like the user’s original intent or key constraints they stated at the beginning of the conversation.
Recursive summarization is more sophisticated. An LLM is used to generate a running summary of the conversation so far, replacing the verbose transcript with a condensed version that preserves the key facts and decisions. This maintains semantic fidelity at a much lower token cost, though it introduces its own latency and the risk of summarization drift over many iterations.
Sessions in Multi-Agent Systems
When you move from a single agent to a multi-agent architecture, session management becomes significantly more complex. The core question becomes: do agents share a session, or does each maintain its own?
In orchestrator-worker patterns, a central agent delegates sub-tasks to specialized agents. The orchestrator typically maintains the primary session with the user, while worker agents may operate with their own ephemeral sessions that capture only the context relevant to their specific sub-task. The orchestrator is then responsible for synthesizing their outputs back into the main session.
In peer-to-peer architectures, agents communicate laterally, and the session management challenge shifts to ensuring that each agent has access to the shared context it needs without being overwhelmed by irrelevant inter-agent chatter.
The key production consideration here is interoperability. In real-world systems, you may have agents built on different frameworks. A memory manager that operates as a specialized, decoupled service using framework-agnostic data structures (simple strings and dictionaries) provides the foundation for multi-agent interoperability, allowing agents built on different stacks to connect to a single shared memory store.
Production Hardening for Sessions
Moving sessions to production introduces three non-negotiable requirements:
Security and privacy demand strict isolation. A session is owned by a single user, and the system must enforce this through access control lists. Every request must be authenticated and authorized against the session owner. A critical best practice is to redact PII before writing to storage – this dramatically reduces the blast radius of a potential data breach and simplifies compliance with regulations like GDPR and CCPA.
Data integrity requires versioned session states with optimistic locking to prevent race conditions in concurrent environments. You need clear lifecycle management policies including TTL-based expiration and automated cleanup.
Performance means sub-second latency for session reads and writes, which typically requires in-memory caching layers backed by persistent storage for durability.
Part II: Memory – The Engine of Long-Term Intelligence
If a session is your workbench, then memory is your filing cabinet. When a project on the workbench is finished, you do not shove the entire messy desk into storage. Instead, you review the materials, discard the rough drafts and redundant notes, and file away only the most critical, finalized documents into labeled folders. This ensures the filing cabinet remains a clean, reliable, and efficient source of truth for all future projects.
This is precisely what a well-designed memory system does. It transforms an agent from a basic chatbot into something genuinely intelligent by enabling three critical capabilities: personalization (remembering user preferences and history), context window management (compacting long conversations into essential facts), and cross-session continuity (maintaining coherent interactions over days, weeks, and months).
Memory and sessions share a deeply symbiotic relationship. Sessions are the primary data source for generating memories, and memories are a key strategy for managing the size of a session. A memory is a snapshot of extracted, meaningful information – a condensed representation that preserves important context and is persisted across sessions to create a continuous, personalized experience.
The Memory Architecture Stack
To build an effective memory system, I think in terms of five interconnected components:
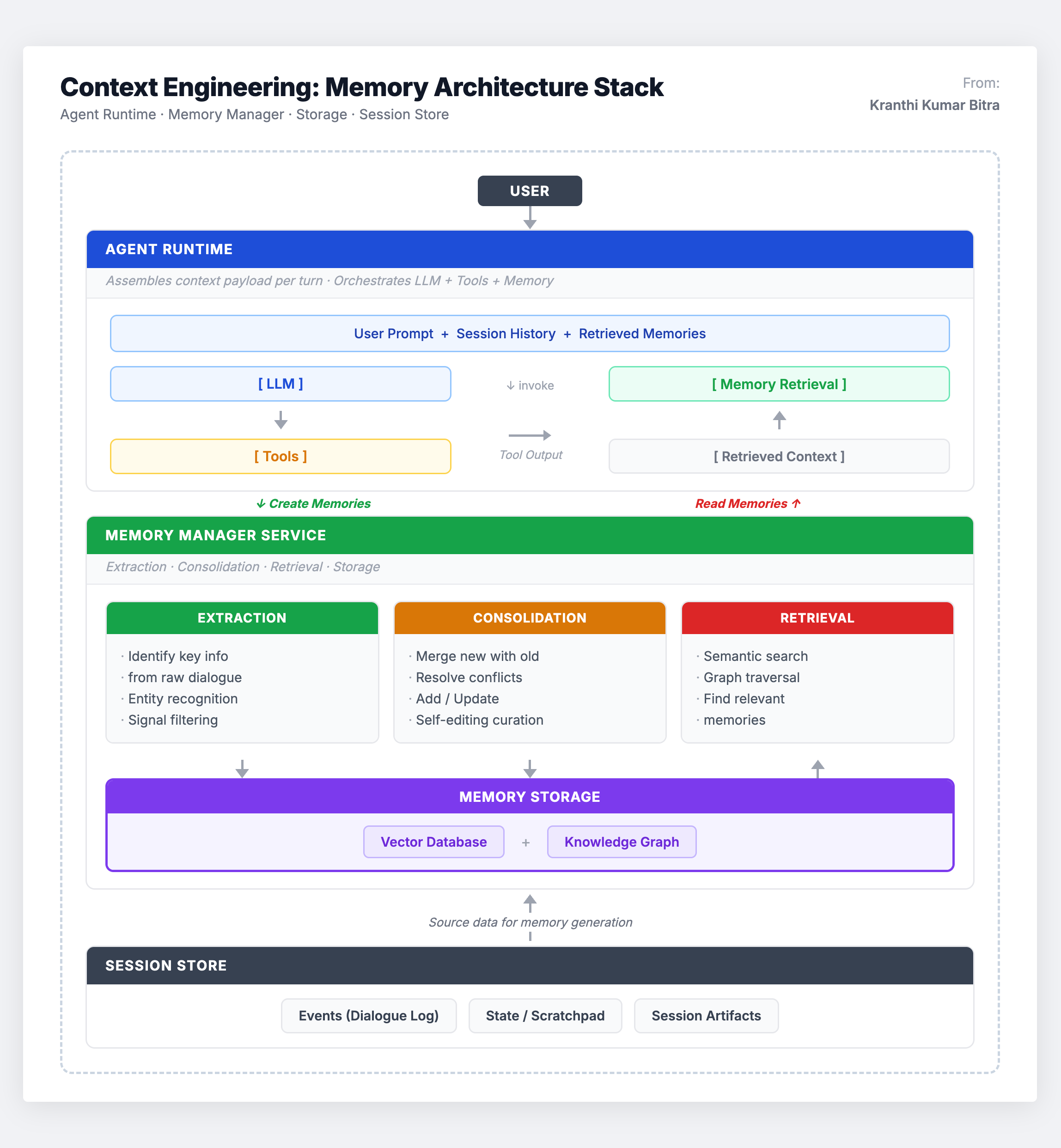
It is critical to recognize that a memory manager is an active system, not just a passive vector database. While it uses similarity search for retrieval, its core value lies in the intelligent extraction, consolidation, and curation pipeline that runs on top of that storage layer.
The Memory Taxonomy
Through my work, I have found it essential to classify memories along multiple dimensions to design effective systems. Let me walk through the taxonomy that I use.
By Duration:
Short-term memory corresponds to the session itself – the immediate working context of a single conversation. Long-term memory persists across sessions and forms the foundation of the agent’s accumulated knowledge about the user and the world.
By Cognitive Function:
This is where the taxonomy gets particularly interesting, drawing from cognitive science frameworks that map surprisingly well to agent architectures:

By Information Role:
This is the dimension I find most architecturally relevant. At the highest level, an agent’s memory serves two fundamentally different purposes:
Knowledge Memory is the agent’s passive, static repository of objective, globally valid, and verifiable information. Think of it as the agent’s internal reference library. It contains canonical facts, universal rules, established procedures, and general truths. This memory is typically pre-loaded, slowly updated, and context-independent. In a shopping assistant, this would be the product catalog and return policies.
Experience Memory is the agent’s active, dynamic record of its interactions and learned behaviors. This is proactive, personalized, situated in a specific context, and task-specific. It includes multi-turn dialogues, action-observation sequences, and explicit or implicit feedback signals. In a shopping assistant, this would be the user’s purchase history, stated preferences, and browsing patterns.
The distinction between knowledge and experience memory has profound implications for how you design your storage, retrieval, and evolution mechanisms. I will return to this theme throughout this post.
Organization Patterns
How memories are organized in storage determines the system’s personality and capabilities. I work with three primary patterns:
Unstructured knowledge bases store each memory as an individual, independent entry (a string or text blob). This is the simplest approach and works well for agents that need to recall a wide variety of independent facts about a user. Each memory stands on its own.
Structured user profiles organize memories as a set of core facts about a user, like a contact card that is continuously updated with stable information. This pattern is optimized for quick lookups of essential, factual information – names, preferences, account details.
Rolling summaries consolidate all information into a single, evolving natural-language document that represents a summary of the entire user-agent relationship. Instead of creating individual memories, the manager continuously updates this one master document. This pattern is frequently used to compact long sessions while preserving the essential narrative.
Storage Architectures: The Vector-Graph Spectrum
The storage architecture is a critical decision that determines how quickly and intelligently an agent can retrieve memories. The choice defines whether the agent excels at finding conceptually similar ideas, understanding structured relationships, or both.
Vector databases are the most common approach, enabling retrieval based on semantic similarity rather than exact keywords. Memories are converted into embedding vectors, and the database finds the closest conceptual matches. This excels at retrieving thematically relevant content even when the exact wording differs. The limitation is that vector search treats every memory as an isolated point in space – it has no concept of how memories relate to each other.
Knowledge graphs store memories as a network of entities and their explicit relationships. Every fact is a triple: (head entity, relation, tail entity). This enables multi-hop reasoning, where the system can traverse chains of relationships to answer complex queries that require connecting multiple facts. The limitation is higher construction and maintenance cost.
The most capable production systems use a hybrid approach – vector databases for broad semantic recall combined with knowledge graphs for precise relational reasoning.
Part III: The Memory Generation Pipeline
This is where the real engineering happens. Memory generation is the process that autonomously transforms raw conversational data into structured, meaningful insights. I think of it as an LLM-driven ETL (Extract, Transform, Load) pipeline that distinguishes a real memory manager from a simple RAG database.
Rather than requiring developers to manually specify database operations, a memory manager uses an LLM to intelligently decide when to add, update, or merge memories. This automation is the core strength – it abstracts away the complexity of managing the database contents, chaining together LLM calls, and deploying background services for data processing.
Stage 1: Ingestion
The process begins when raw data – typically a conversation history or session transcript – is provided to the memory manager. This is the starting point: unprocessed, verbose dialogue containing both signal and noise.
Stage 2: Extraction
The goal of extraction is to answer a fundamental question: “What information in this conversation is meaningful enough to become a memory?” This is not simple summarization. It is a targeted, intelligent filtering process designed to separate the signal (important facts, preferences, goals) from the noise (pleasantries, filler text, conversational scaffolding).
What counts as “meaningful” is not universal – it is defined entirely by the agent’s purpose and use case. A customer support agent needs to remember order numbers and technical issues. A personal wellness coach needs to remember long-term goals and emotional states. Customizing what information is preserved is the key to creating a truly effective agent.
The extraction process operates across multiple data modalities:
From text and dialogue: The system performs structured information extraction, identifying entities, attributes, and relationships. It encodes semantic content into dense vector representations for similarity-based retrieval. And it applies summarization to condense lengthy exchanges into concise memory fragments.
From sequential trajectories: For action-observation sequences, extraction captures temporal structure through event segmentation with timestamps, dynamic state snapshots at key moments, and pattern mining to discover recurring behavioral routines.
From multimodal data: For sensory inputs like images or audio, extraction bridges the gap between raw signals and semantic meaning through description generation, interactive content detection, and joint embedding into unified vector spaces.
Stage 3: Consolidation
Consolidation is the most sophisticated stage. This is where the memory manager handles conflict resolution and deduplication, performing a self-editing process that compares newly extracted information with existing memories to ensure the knowledge base remains coherent, accurate, and evolves over time.
The manager evaluates each new memory and can decide to:
Add the new memory as a fresh entry when it represents genuinely novel information. Merge it into an existing memory when it provides additional detail about a known topic. Update an existing memory when the new information supersedes outdated data. Discard it when the information is redundant or irrelevant.

Memory Provenance: Trust and Lineage
One of the aspects that separates production memory systems from prototypes is provenance tracking. A single memory might be derived from multiple data sources, and a single source might contribute to multiple memories. Understanding this lineage is critical for two reasons: it dictates the weight each source has during consolidation, and it informs how much the agent should rely on that memory during inference.
I categorize data sources into three trust tiers:
Bootstrapped data is information pre-loaded from internal systems like a CRM. This is high-trust data that can initialize a user’s memory profile and address the cold-start problem – the challenge of personalizing for a user the agent has never interacted with.
User input includes data provided explicitly (via forms – high trust) or extracted implicitly from conversation (generally lower trust, since users may be speculative, sarcastic, or imprecise).
Tool output is data returned from external API calls. Generating permanent memories from tool output is generally discouraged because these memories tend to be brittle and stale, making them better suited for short-term caching.
Confidence in a memory should evolve over time. It increases through corroboration – when multiple trusted sources provide consistent information. And the system must actively prune memories through time-based decay (old memories lose relevance), low-confidence removal (unverified inferences get pruned), and contradiction-based invalidation (new facts override old ones).
Part IV: Graph-Based Memory – The Next Frontier
Everything I have described so far represents the current state of production memory systems. But the most exciting developments I am tracking are in graph-based memory architectures, which represent a fundamental paradigm shift in how we think about agent memory.
The core idea is elegantly simple: instead of storing memories as isolated entries in a flat database, we model memory content as a dynamic, structured graph. Memory units – events, entities, concepts, observations – become nodes. The semantic, temporal, causal, and logical relationships between them become edges. This explicit structural representation transforms memory from a flat list into a rich, interconnected network of knowledge.
Why Graphs Change Everything
Traditional memory systems treat memories as independent data points floating in a vector space. Graph-based memory makes relationships first-class citizens. This distinction matters enormously in practice because it unlocks four capabilities that flat memory architectures struggle with:

A critical insight is that traditional memory forms are actually degenerate cases within the graph paradigm. A linear buffer is just a chain graph. A vector memory can be interpreted as a fully-connected graph with similarity-weighted edges. Graph-based memory does not replace existing designs – it provides a unified and extensible framework that subsumes them.
Graph Construction Paradigms
The choice of graph structure is not one-size-fits-all. Different types of memory benefit from different graph architectures. Here is the taxonomy I use when evaluating options:
GRAPH CONSTRUCTION PARADIGM COMPARISON
PARADIGM BEST FOR TRADE-OFF
─────────────────────────────────────────────────────────────────
Knowledge Graph Semantic memory. High interpretability
(entity-relation- Stores factual knowledge but expensive to
entity triples) as structured triples. construct and maintain.
Multi-hop factual Struggles with fuzzy
reasoning. or unstructured info.
─────────────────────────────────────────────────────────────────
Temporal Graph Episodic & short-term Explicit time modeling
(timestamped memory. Captures event but complex queries
events + edges) sequences and transient over time windows.
state changes. Storage overhead.
─────────────────────────────────────────────────────────────────
Hierarchical Graph Procedural & episodic Intuitive top-down
(tree/cluster memory. Compresses retrieval at multiple
structures) experience into abstraction levels.
multi-level summaries. Rigid structure.
─────────────────────────────────────────────────────────────────
Hypergraph Associative memory. Preserves n-ary
(n-ary edges) Connects multiple relationships without
entities in a single information loss.
relationship. Computationally costly.
─────────────────────────────────────────────────────────────────
Hybrid Graph Semantic + episodic + Integrates multiple
(combined working memory. Fuses sources and structures.
architectures) facts with experience Most flexible but
via routing layers. complex to implement.
─────────────────────────────────────────────────────────────────
The knowledge-experience decoupling pattern is particularly powerful. The idea is to separate static world knowledge (stored in a directed knowledge graph of immutable rules and facts) from dynamic agent experience (stored in a vector pool of interaction trajectories). This separation allows the agent to ground its planning in rigid graph-based knowledge while refining its execution through retrieval-augmented experience.
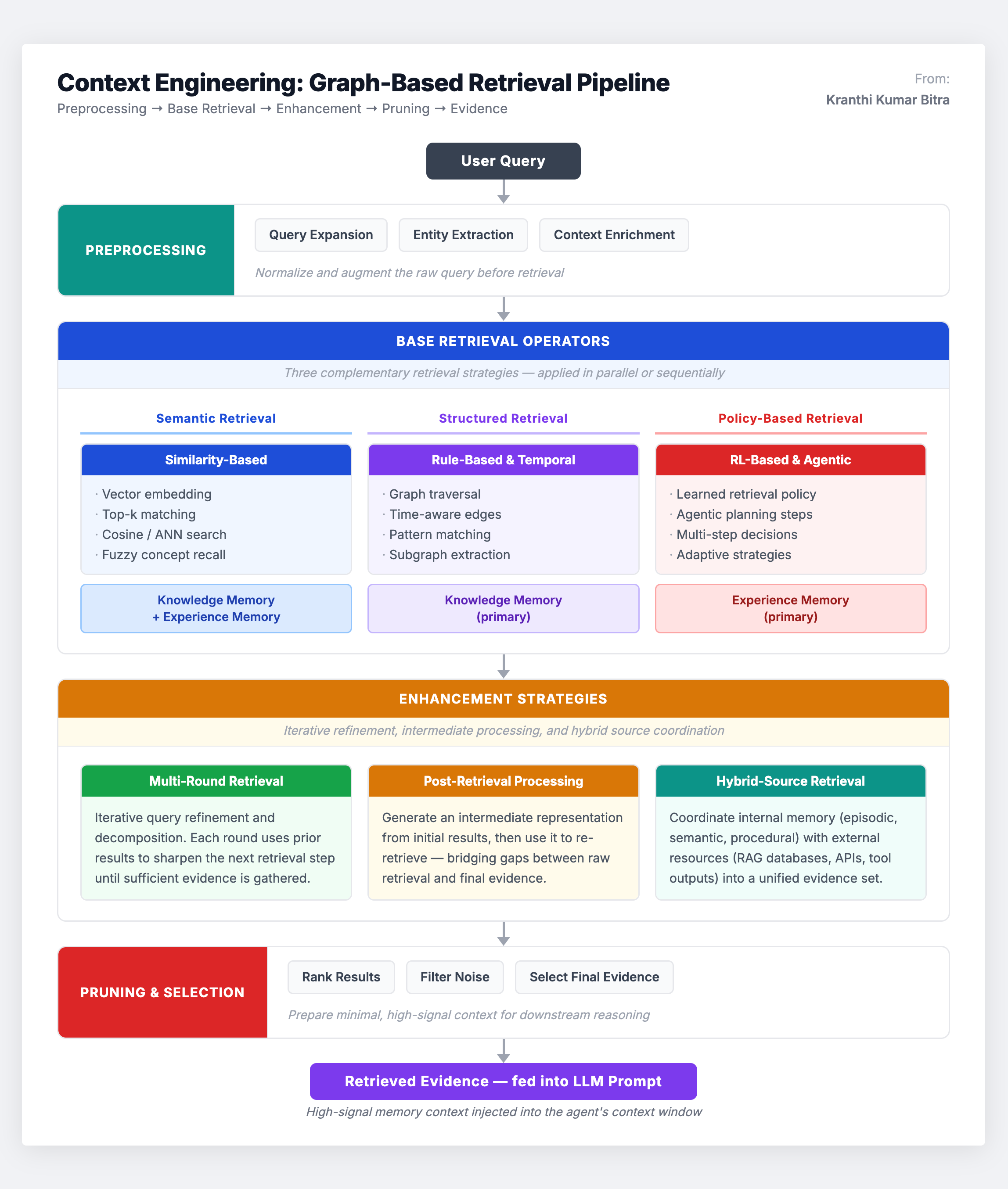
Retrieval: Three Paradigms
Graph-based retrieval operates through three complementary paradigms, each serving different memory types and query patterns:
Semantic retrieval uses similarity-based operators over extracted text and embeddings. It supports fuzzy matching and basic concept alignment and is often used as a candidate generator for both knowledge and experience memory. This is your broad-net approach.
Structured retrieval includes rule-based, temporal, and graph-based operators that execute explicit constraints over knowledge graphs, hierarchies, and hypergraphs. This enables verifiable and interpretable evidence selection – each retrieval decision is traceable through the underlying graph structure. Structured retrieval is particularly central to knowledge memory, where correctness and consistency are primary concerns.
Policy-based retrieval uses reinforcement learning and agentic operators that treat retrieval as sequential decision-making. The system selects which memory type to query, chooses which operators to apply, allocates computational budgets, and decides when to stop retrieval. This is especially important for experience memory, which is dynamic, personalized, and time-sensitive.
In practice, the most effective systems combine these paradigms in a pipeline: semantic anchoring to identify candidate regions, followed by structured expansion to traverse relevant subgraphs, followed by policy-controlled stopping and pruning to manage computational costs.
Memory Evolution: Learning Over Time
Static memory is dead memory. As agents interact with dynamic environments over extended periods, their memory must evolve to incorporate new information, resolve inconsistencies, and adapt to changing contexts. Graph-based structures are particularly well-suited for evolution because their explicit modeling of relational connections, temporal dependencies, and validity enables direct updates through node, edge, and subgraph operations.
I see memory evolution operating through two complementary mechanisms:
Internal self-evolution involves introspective refinement without new external input. This includes memory consolidation (merging similar subgraph instances into generalized schema nodes to reduce redundancy), inference and conflict resolution (detecting implicit contradictions between nodes and triggering self-correction based on confidence scores or temporal recency), and latent link prediction (using the LLM to predict potential relationships between disconnected subgraphs, mimicking associative thinking in human cognition).
External self-exploration involves grounding memory through environmental interaction. This includes reactive feedback-driven adaptation (updating the graph based on success/failure signals from the environment) and proactive active inquiry (the agent autonomously seeking new information to fill identified gaps in its knowledge graph).
This capacity for an agent to self-evolve its logic invites comparison to fine-tuning via RLHF. The key difference is that fine-tuning is a slow, offline process that alters model weights. Memory-based adaptation is fast, online, and dynamic – injecting the correct playbook into the prompt through in-context learning without requiring any retraining.
Part V: Procedural Memory – Teaching Agents How, Not Just What
Most discussions about agent memory focus on declarative knowledge – facts, preferences, and historical records. But some of the most impactful work I have done involves procedural memory: the ability for an agent to remember and improve upon its own operational strategies.
Procedural memory encodes skills, routines, and reusable workflows. It represents “how-to” knowledge – standard operating procedures, successful problem-solving strategies, and optimized task execution patterns. Where declarative memory captures the “what,” procedural memory captures the “how.”
This requires a completely separate and specialized lifecycle:
Procedural extraction uses specialized prompts designed to distill a reusable strategy or playbook from a successful interaction, rather than just capturing a fact.
Procedural consolidation curates the workflow itself. This is an active logic management process focused on integrating new successful methods with existing best practices, patching flawed steps in a known plan, and pruning outdated or ineffective procedures.
Procedural retrieval aims not to retrieve data for answering a question, but to retrieve a plan that guides the agent on how to execute a complex task. This often requires a different data schema than declarative memories.

Part VI: Putting Memory Into Production
Building a memory system that works in a notebook is straightforward. Building one that works at enterprise scale is a fundamentally different challenge. Here are the production considerations I prioritize.
Scalability and Resilience
As an application grows, the memory system must handle high-frequency events without failure. Given concurrent requests, you need to prevent deadlocks and race conditions when multiple events modify the same memory. Transactional database operations or optimistic locking can help, though they introduce queuing when multiple requests target the same memories. A robust message queue is essential to buffer high volumes and prevent the memory generation service from being overwhelmed.
The memory service must be resilient to transient errors. If an LLM call fails during extraction or consolidation, the system should use retry mechanisms with exponential backoff and route persistent failures to a dead-letter queue for analysis.
For global applications, the memory manager must use a database with built-in multi-region replication. Client-side replication is not feasible because consolidation requires a single, transactionally consistent view of the data to prevent conflicts. The memory system must handle replication internally, presenting a single logical datastore while ensuring global consistency.
Asynchronous by Default
Memory generation is an expensive operation requiring LLM calls and database writes. In production, memory generation should almost always be handled asynchronously as a background process. After the agent sends its response to the user, the memory pipeline runs in parallel without blocking the user experience. A synchronous approach where the user waits for memory to be written before receiving a response creates an unacceptably slow experience. This necessitates that memory generation occurs in a service architecturally separate from the agent’s core runtime.
Security and Privacy: The Filing Cabinet Analogy
I think of the security model as managing a secure corporate archive. The cardinal rule is data isolation – memory must be strictly isolated at the user or tenant level. An agent serving one user must never access another user’s memories, enforced through restrictive ACLs. Users must have programmatic control over their data, including the ability to opt out of memory generation or request complete deletion.
Before filing any document, the system must redact sensitive PII, ensuring knowledge is saved without creating liability. Equally important is guarding against memory poisoning – validating and sanitizing information before committing it to long-term memory to prevent a malicious user from corrupting the agent’s persistent knowledge through prompt injection.
There is also an exfiltration risk when multiple users share procedural memories. If a procedural memory from one user is used as a template for another, rigorous anonymization must be applied to prevent sensitive information from leaking across user boundaries.
Testing and Evaluation
A production memory system demands continuous evaluation across multiple dimensions:
Extraction quality measures whether the system correctly identifies meaningful information and avoids capturing noise. You evaluate this against ground-truth datasets with known important facts.
Retrieval relevance measures whether the right memories are surfaced for a given query. Standard information retrieval metrics apply – precision, recall, and ranking quality.
End-to-end task success is the ultimate test: does memory actually help the agent perform its job better? This requires evaluating the agent’s performance on downstream tasks with and without memory, often using an LLM judge to compare outputs against golden answers.
Evaluation is not a one-time event. It is an engine for continuous improvement – establishing baselines, analyzing failures, tuning the system, and re-evaluating to measure impact.
Part VII: Real-World Applications Across Domains
The memory architectures I have described are not theoretical constructs. They are being deployed across a wide range of domains, each with unique requirements that stress-test different aspects of the memory lifecycle.
Conversational AI and dialogue systems benefit most directly from memory architectures that maintain context across multi-session interactions. The key challenge is connecting fragmented dialogue sessions into coherent knowledge graphs that enable precise recall. Semantic graphs that link topics across conversations have proven particularly effective for maintaining continuity without losing the nuance of individual exchanges.
Software engineering agents face unique memory challenges because code has rigid structural requirements and logical dependencies. Effective memory for code agents requires modeling the information space of a software repository as something resembling a knowledge graph of file dependencies and logical relationships. Tree-based architectures that handle non-linear dependencies in code generation through divide-and-conquer approaches have shown strong results.
Recommender systems apply memory to address the challenge of long, dynamic user histories. The most effective approaches use a three-level memory hierarchy: coarse-grained history retrieval for scalability, structured key-value memory for semantic organization, and cognitive memory with reflection and planning for active preference modeling.
Financial agents require memory systems with high priority for recency and the ability to balance learned patterns with the latest market conditions. The information decay pattern in financial markets – where yesterday’s insight might be irrelevant today – demands temporal knowledge graphs with aggressive pruning policies.
Healthcare agents need memory to retain patient histories over multiple visits, integrate new medical knowledge, perform differential diagnosis, and provide personalized care. The stakes here are highest, requiring structured and interaction-aware memory with strong provenance tracking and interpretability guarantees.
Robotics and embodied agents must continuously ground their decision-making in the physical world, which is dynamic and partially observable. Memory must bridge high-level language instructions and executable actions, often through dual architectures that separate perception stability from long-term maintenance.
Looking Forward: Where This Is All Heading
The trajectory I see for agent memory systems is clear: from flat, passive storage toward active, self-evolving knowledge networks that can reason about their own content. Several developments are converging to make this possible.
Dynamic graph construction is moving beyond static knowledge graph building toward systems that can construct and modify their graph structures on the fly as new information arrives. This is essential for agents that operate in rapidly changing environments.
Temporal reasoning at scale remains an open challenge. Current temporal graph implementations work well for small-to-medium knowledge bases, but scaling temporal queries across millions of events while maintaining chronological consistency requires new algorithmic approaches.
Cross-modal memory integration – combining text, vision, audio, and structured data into unified memory representations – is becoming increasingly important as agents become multimodal. The challenge is not just storing multimodal content, but enabling retrieval that works across modalities.
Memory-augmented reinforcement learning is an emerging area where the agent’s memory graph is directly incorporated into the reward and policy optimization loop, creating a tight feedback cycle between memory evolution and behavioral improvement.
The agents that will dominate the next phase of AI deployment will not be the ones with the most capable language models. They will be the ones with the most intelligent memory systems – architectures that can acquire, organize, retrieve, and evolve knowledge with the kind of precision and adaptability that makes an AI assistant genuinely useful over the long term.
The memory architecture you choose today will define the ceiling of your agent’s intelligence tomorrow. Choose wisely.
This post reflects my own analysis and architectural understanding developed through hands-on experience building and deploying AI agent systems. The frameworks and taxonomies presented here are synthesized from my work in the field and represent patterns I have found consistently effective in production environments.