
Evaluation Engineering for LLM Systems: Why Testing AI Scores Is a Discipline of Its Own
“A score of 0.87 means nothing in isolation. What matters is what the system does because of it — and whether it still does it next week.”

TL;DR
If your AI evaluation strategy relies on exact score assertions, a happy-path-only golden dataset, or threshold checks alone, it will fail in production — quietly and predictably. This post introduces evaluation engineering: the discipline of designing measurement systems, test strategies, and quality gates for AI components that produce continuous, probabilistic, non-deterministic output. By the end, you will have five testing patterns, a four-layer CI/CD architecture, a complete RAG evaluation model, and an infrastructure checklist to take into your next sprint.
Who This Is For
This post is written for engineers who are shipping AI-powered systems — not researching them. Specifically:
- Software engineers integrating LLM or embedding APIs into production services
- Automation engineers designing test strategies for AI components
- Tech leads setting quality gates for AI-adjacent pipelines
- Anyone who has shipped an AI feature and been surprised when it degraded silently
If you are still in the “it works in my notebook” phase, bookmark this for when you move to production. The problems described here do not appear until you do.
The Assumption That Breaks in Production
There is a quiet assumption embedded in most AI integration projects: that once a model works, testing it is roughly the same as testing any other software. You call the API, you get a response, you assert the response looks right. Done.
That assumption breaks — badly — the moment you ship. Scores drift. Results that were stable in staging become erratic in production. A model upgrade that seemed harmless rewrites the entire semantic landscape overnight. A retrieval pipeline that tested perfectly returns confidently wrong answers on real queries.
This is not a tooling problem. It is a conceptual problem — a gap in how we think about what it means for an AI-powered system to be correct.
This post is about closing that gap, specifically through the lens of evaluation engineering: the discipline of designing measurement systems, test strategies, and quality gates for AI components that produce continuous, probabilistic, non-deterministic output.
The Fundamental Problem: You Cannot Assert a Probability
When you test a REST API endpoint, you can assert that GET /users/42 returns a JSON object with a specific shape and that the id field equals 42. The output is deterministic. The same input always produces the same output.
LLM similarity scores are not like this. The same two tickets compared against each other on two consecutive requests can return 0.87 and 0.84. Neither value is wrong. They are both samples from a probability distribution shaped by the model’s stochastic internals, floating-point precision, infrastructure state, and — if a retrieval layer is involved — the current composition of the vector index.
The first engineering decision in LLM evaluation is accepting this, completely, and designing your test strategy around it rather than against it.
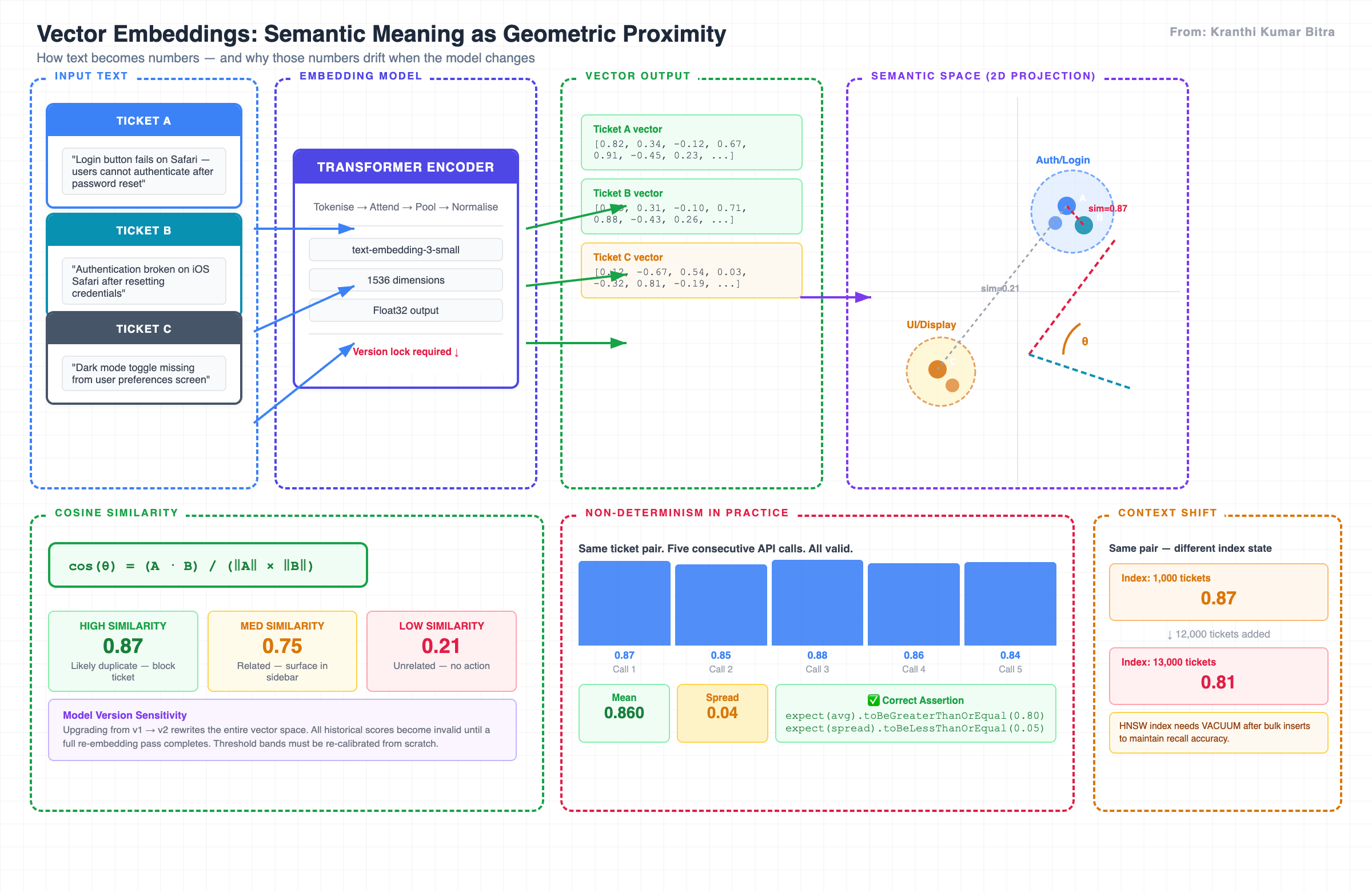
Vector embeddings map text into high-dimensional space. Semantic similarity becomes geometric proximity — and that geometry shifts when the model that produced the embeddings is updated.
Three properties define how LLM scores behave in production:
| Property | What It Means | What It Breaks |
|---|---|---|
| Non-determinism | The same input produces a slightly different output on each call | Any exact equality assertion |
| Context sensitivity | Adding new data to the vector index shifts scores for existing pairs | Tests that pass in isolation but fail as the index grows |
| Model version sensitivity | An embedding model upgrade rewrites the entire vector space | Pre-upgrade baselines become invalid without a full re-embedding pass |
Understanding these three properties is the prerequisite for everything that follows.
Five Patterns for Comparing Similarity Scores
Rather than a single testing approach, evaluation engineering offers a set of patterns — each suited to a different stage of the delivery pipeline and a different risk profile. The key insight is that they are not interchangeable: each one detects a different class of problem.

Five patterns, three distinct failure classes: correctness (P1–P3), instability (P4), and gradual degradation (P5). A complete strategy requires all five.
Pattern 1 — Threshold Band Assertion
The simplest and most important pattern. Instead of asserting an exact score, assert that the score falls within a pre-defined acceptable band.
// ❌ This will create flaky tests — fails on any infra change, model update, or index event
expect(score).toBe(0.87);
// ✅ This is stable across model variance
expect(score).toBeGreaterThanOrEqual(0.80);
expect(score).toBeLessThanOrEqual(1.00);
# Same principle in Python
assert 0.80 <= score <= 1.00 # HIGH band — likely duplicate
assert score < 0.50 # TRUE NEGATIVE — unrelated content
The band boundaries are not arbitrary — they encode business logic. A score of 0.92 should trigger a duplicate warning and block ticket creation. A score of 0.75 should surface a related ticket in the sidebar. These thresholds are engineering decisions that must be made explicit, documented, and agreed across dev and automation teams before a single test is written.
Six band categories your golden dataset must cover: HIGH (≥0.90), MEDIUM (0.70–0.89), LOW (0.50–0.69), TRUE NEGATIVE (<0.50), ADVERSARIAL pairs, and EDGE CASES. Omitting the last three tells you only whether the system works when it should. It tells you nothing about whether it fires when it should not.
Pattern 2 — Relative Ranking Assertion
Rather than asserting what a score is, assert what it is relative to. A known duplicate should always score higher than a known related-but-not-duplicate ticket. This ordering is far more stable across model updates than absolute values.
const scoreDuplicate = await getMatchScore(query, "ADO-1042"); // confirmed duplicate
const scoreRelated = await getMatchScore(query, "ADO-2205"); // related but distinct
// The gap matters more than either individual value
expect(scoreDuplicate - scoreRelated).toBeGreaterThan(0.08);
This pattern is particularly valuable during prompt changes, preprocessing pipeline modifications, or when switching embedding models — scenarios where absolute scores will shift but relative ordering should remain stable. Use it as a first regression signal after any change that touches the similarity pipeline.
Pattern 3 — Golden Dataset with Tolerance
Maintain a human-curated dataset of (query, expected_match, expected_score) triples. On each evaluation run, compare the actual score against the expected score with a ±0.05 tolerance window.
// golden-dataset.json — version-controlled, human-annotated, reviewed quarterly
test.each(goldenDataset)(
"[$id] score within tolerance of $expectedScore",
async (tc) => {
const actual = await querySimilarity(tc.query, tc.match);
expect(Math.abs(actual - tc.expectedScore)).toBeLessThanOrEqual(0.05);
}
);
The critical constraint that most teams violate: The expectedScore values must be set by a human reviewing real system outputs — not generated by the LLM being tested. Asking the model to evaluate its own outputs is not testing; it is self-validation, and it produces exactly the kind of false confidence that causes production incidents.
The golden dataset is the most important artifact the automation team produces. It must be human-curated from real historical tickets, annotated by engineers who actually triaged those issues, version-controlled in the test repository, and extended continuously as new failure patterns are discovered.
Pattern 4 — Multi-Run Statistical Averaging
For high-stakes assertions — particularly duplicate detection that blocks ticket creation — a single run is not a reliable basis for a pass/fail decision. Run the same case N times and assert against the mean and the variance.
const scores = await Promise.all(
Array.from({ length: 5 }, () => querySimilarity(query, match))
);
const avg = mean(scores);
const spread = max(scores) - min(scores);
expect(avg).toBeGreaterThanOrEqual(0.80); // quality gate on the central tendency
expect(spread).toBeLessThanOrEqual(0.05); // stability gate on the variance
scores = [query_similarity(query, match) for _ in range(5)]
avg = statistics.mean(scores)
spread = max(scores) - min(scores)
assert avg >= 0.80, f"Quality gate failed: mean {avg:.3f}"
assert spread <= 0.05, f"Stability gate failed: spread {spread:.3f}"
The variance assertion is as important as the mean assertion. A system that scores 0.95 on one run and 0.74 on the next has a serious stability problem — potentially in infrastructure, connection pool, or index state — that a mean-only check would miss entirely.
Pattern 5 — Drift Detection Against Baseline
This is the most mature pattern and the one most commonly missing from AI test suites. It operates nightly, not per-PR. It stores historical mean scores for a fixed set of anchor pairs, and on each run it computes the delta between the current score and the stored baseline.
const currentMean = mean(scores);
const baselineMean = await readBaseline(pair.id);
const drift = baselineMean - currentMean;
if (drift > 0.03) {
await alertSlack(`[DRIFT] ${pair.id}: ${baselineMean.toFixed(3)} → ${currentMean.toFixed(3)}`);
await createJiraDefect({ pair: pair.id, drift, baseline: baselineMean, current: currentMean });
}
await writeBaseline(pair.id, currentMean);
The value of drift detection is that it catches what threshold testing cannot: gradual, incremental degradation. A score that moves from 0.943 to 0.908 over four weeks will never trigger a per-PR threshold gate. It will trigger a drift alert in week four — which is when you want to investigate, before engineers start filing complaints about duplicate tickets being missed.
The key relationship between patterns: Patterns 1–3 detect correctness. Pattern 4 detects instability. Pattern 5 detects degradation. A complete evaluation strategy needs all five.
When RAG Enters the Picture
Everything above assumes a single pipeline: input goes in, a score comes out. A RAG (Retrieval-Augmented Generation) pipeline is fundamentally different. It has two failure modes that are completely independent of each other — and a high final score can mask either one.
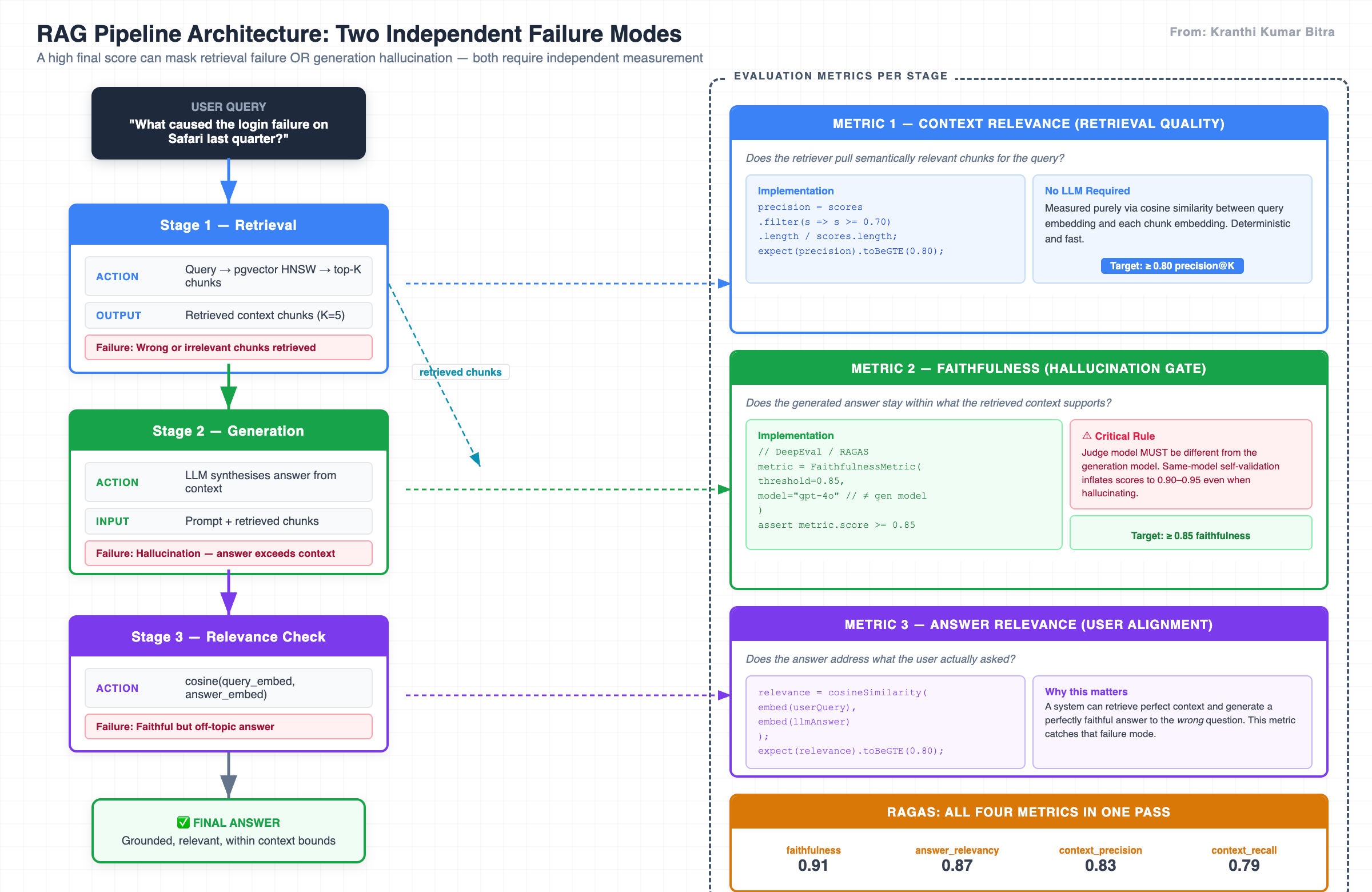
A RAG pipeline has two independent components: retrieval and generation. Testing only the final answer similarity is like testing a relay race by only checking the finish line time — you learn whether the race was won, not which runner dropped the baton.
The pipeline structure exposes three distinct evaluation dimensions:
User Query
│
▼
[RETRIEVAL] ←── Did the system pull the right documents?
│ retrieved chunks
▼
[GENERATION] ←── Did the model use those documents faithfully?
│ answer
▼
[RELEVANCE] ←── Does the answer actually address the question?
Dimension 1 — Context Relevance
Does the retriever pull semantically relevant chunks for the query? This is measured deterministically using cosine similarity between the query embedding and each retrieved chunk — no LLM required.
const queryVec = await embedText(query);
const scores = await Promise.all(
chunks.map(async c => cosineSimilarity(queryVec, await embedText(c.text)))
);
const precision = scores.filter(s => s >= 0.70).length / scores.length;
expect(precision).toBeGreaterThanOrEqual(0.80); // at least 80% of chunks are relevant
from sentence_transformers import SentenceTransformer, util
scores = [float(util.cos_sim(q_vec, model.encode(chunk))) for chunk in chunks]
precision = len([s for s in scores if s >= 0.70]) / len(scores)
assert precision >= 0.80
Dimension 2 — Faithfulness
Does the model’s answer stay within the bounds of the retrieved context, or does it introduce information that the context does not support? This is the hallucination gate — and it requires a separate judge model to evaluate.
const result = await evaluateFaithfulness(retrievedChunks, llmAnswer, {
judgeModel: "claude-opus-4-5" // always different from the generation model
});
expect(result.faithfulness_score).toBeGreaterThanOrEqual(0.85);
from deepeval.metrics import FaithfulnessMetric
metric = FaithfulnessMetric(threshold=0.85, model="gpt-4o")
metric.measure(test_case)
assert metric.score >= 0.85
The judge model must be different from the generation model. Using the same model to evaluate its own output creates self-validation bias — a phenomenon where the model consistently rates its own answers as faithful because it is completing the pattern it generated. In practice, this produces faithfulness scores in the 0.90–0.95 range for responses that contain significant hallucination.
Dimension 3 — Answer Relevance
Does the final answer actually address what the user asked? A system can retrieve perfect context and generate a perfectly faithful answer to the wrong question. Answer relevance catches this failure mode.
const relevance = cosineSimilarity(await embedText(userQuery), await embedText(llmAnswer));
expect(relevance).toBeGreaterThanOrEqual(0.80);
The RAGAS Framework
For teams that need systematic RAG evaluation without building all the scaffolding from scratch, RAGAS computes all four standard metrics in a single pass:
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, \
context_precision, context_recall
scores = evaluate(Dataset.from_dict(data), metrics=[
faithfulness, answer_relevancy, context_precision, context_recall
])
# { "faithfulness": 0.91, "answer_relevancy": 0.87,
# "context_precision": 0.83, "context_recall": 0.79 }
Because RAGAS has no TypeScript equivalent, teams using a TypeScript primary stack should run it as a Python nightly job and write the results to a shared JSON report that TypeScript contract tests then read and assert against — bridging the two stacks without duplicating the evaluation logic.
// TypeScript reads the RAGAS output in Layer 2 contract tests
import ragasReport from "../../reports/ragas-latest.json";
expect(ragasReport.faithfulness).toBeGreaterThanOrEqual(0.85);
expect(ragasReport.answer_relevancy).toBeGreaterThanOrEqual(0.80);
The Four-Layer Automation Architecture
With the measurement patterns established, the question becomes how to structure them into a coherent CI/CD strategy. The answer is a four-layer architecture where each layer has a distinct purpose, trigger, gate type, and tooling responsibility.
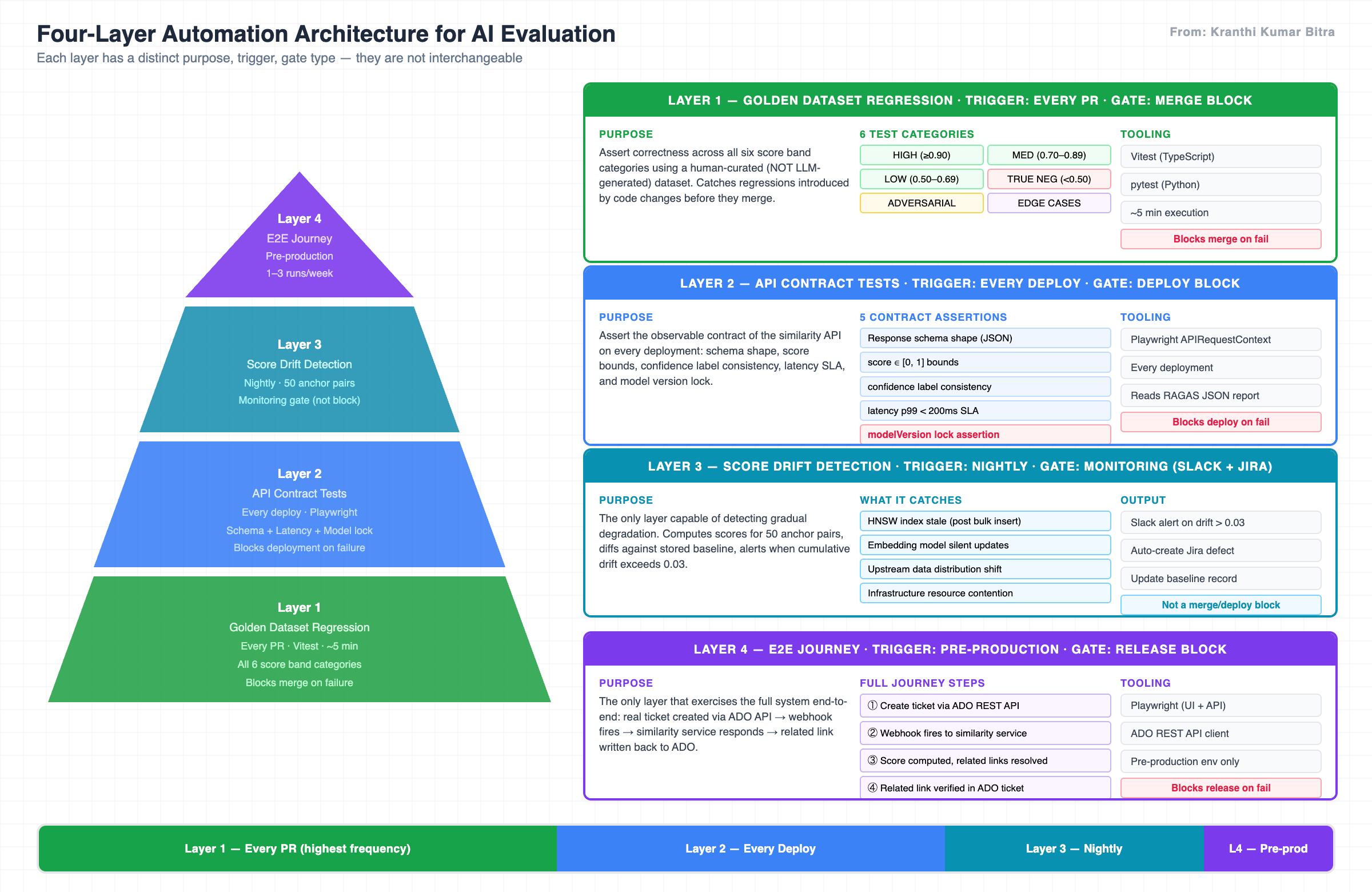
The classic test pyramid applies to AI evaluation — but each layer needs AI-specific thinking about non-determinism, score bands, and drift. The nightly monitoring layer is not a safety net; it is the primary signal for system health over time.
▲
/ \ Layer 4 — E2E Journey
/ \ Full webhook → pipeline → result verification
/─────\
/ \ Layer 3 — Score Drift Detection (nightly)
/ \ Mean vs baseline across 50 anchor pairs
/───────────\
/ \ Layer 2 — API Contract Tests (every deploy)
/ \ Schema, score range [0,1], latency SLA, model lock
/─────────────────\
/ \ Layer 1 — Golden Dataset Regression (every PR)
/ \ Correctness across all six score band categories
/───────────────────────\
Layer 1 runs on every PR in approximately five minutes. It uses the golden dataset to assert that the system correctly places known ticket pairs in their expected score bands. Any failure blocks the merge. This is the primary fast feedback loop for engineers.
Layer 2 runs on every deployment. It uses Playwright’s APIRequestContext to assert the API contract: response schema, score bounds, confidence label consistency, latency SLA, and model version lock. Any failure blocks the deployment. It also reads and asserts against the RAGAS JSON report from the most recent nightly run.
Layer 3 runs nightly at a fixed time. It is not a block gate — it is a monitoring gate. It computes scores for fifty anchor pairs, compares them against stored baselines, and fires Slack alerts and auto-creates Jira defects when drift exceeds the threshold. This is the only layer capable of catching gradual degradation.
Layer 4 runs as a pre-production gate. It is the only layer that exercises the full end-to-end system: a real ticket is created via the ADO API, the webhook fires, the similarity service responds, and the result is validated — including the related link written back to ADO.
| Layer | Trigger | Gate Type | Tooling | Execution Time |
|---|---|---|---|---|
| 1 — Golden Regression | Every PR | Merge block | Vitest / pytest | ~5 min |
| 2 — API Contract | Every deploy | Deploy block | Playwright | ~3 min |
| 3 — Drift Detection | Nightly | Monitoring | Custom + Slack/Jira | ~15 min |
| 4 — E2E Journey | Pre-production | Release block | Playwright + ADO API | ~20 min |
The Role of the Automation Team
A common misunderstanding in AI projects is that the automation team’s job is to verify that the model works. It is not. The automation team cannot verify the model — they do not own it, cannot change it, and cannot predict what a model upgrade will do to the score distribution.
What the automation team can own — and must own — is the quality gate: the continuous evidence that observable system behaviour remains within agreed bounds.
| What Dev Team Owns | What Automation Team Owns |
|---|---|
| Embedding model selection and configuration | Human-curated golden dataset across all six categories |
| pgvector schema, HNSW index, upsert logic | API contract enforcement via Playwright — every deploy |
| Score band threshold proposal | Score band threshold approval and enforcement |
| Faithfulness judge LLM implementation | Faithfulness assertions in the contract test suite |
| Latency SLA definition | Latency assertion in every Layer 2 test |
| Model version management | modelVersion assertion that catches accidental upgrades |
The golden dataset is the most important artifact the automation team produces. It must be human-curated from real historical tickets, annotated by engineers who actually triaged those issues, version-controlled in the test repository, and extended continuously as new failure patterns are discovered. It cannot be generated by the LLM being tested.
The Drift Scenario That Changes How You Think About Testing
Consider this sequence of nightly scores for a single anchor pair over four weeks:
| Week | Mean Score | Delta | Cumulative Drift | L1 Gate | L2 Gate | L3 Drift Alert |
|---|---|---|---|---|---|---|
| Week 1 | 0.943 | — | 0.000 | ✅ Pass | ✅ Pass | No alert |
| Week 2 | 0.941 | -0.002 | 0.002 | ✅ Pass | ✅ Pass | No alert |
| Week 3 | 0.927 | -0.014 | 0.016 | ✅ Pass | ✅ Pass | No alert |
| Week 4 | 0.908 | -0.019 | 0.035 | ✅ Pass | ✅ Pass | 🔴 ALERT |
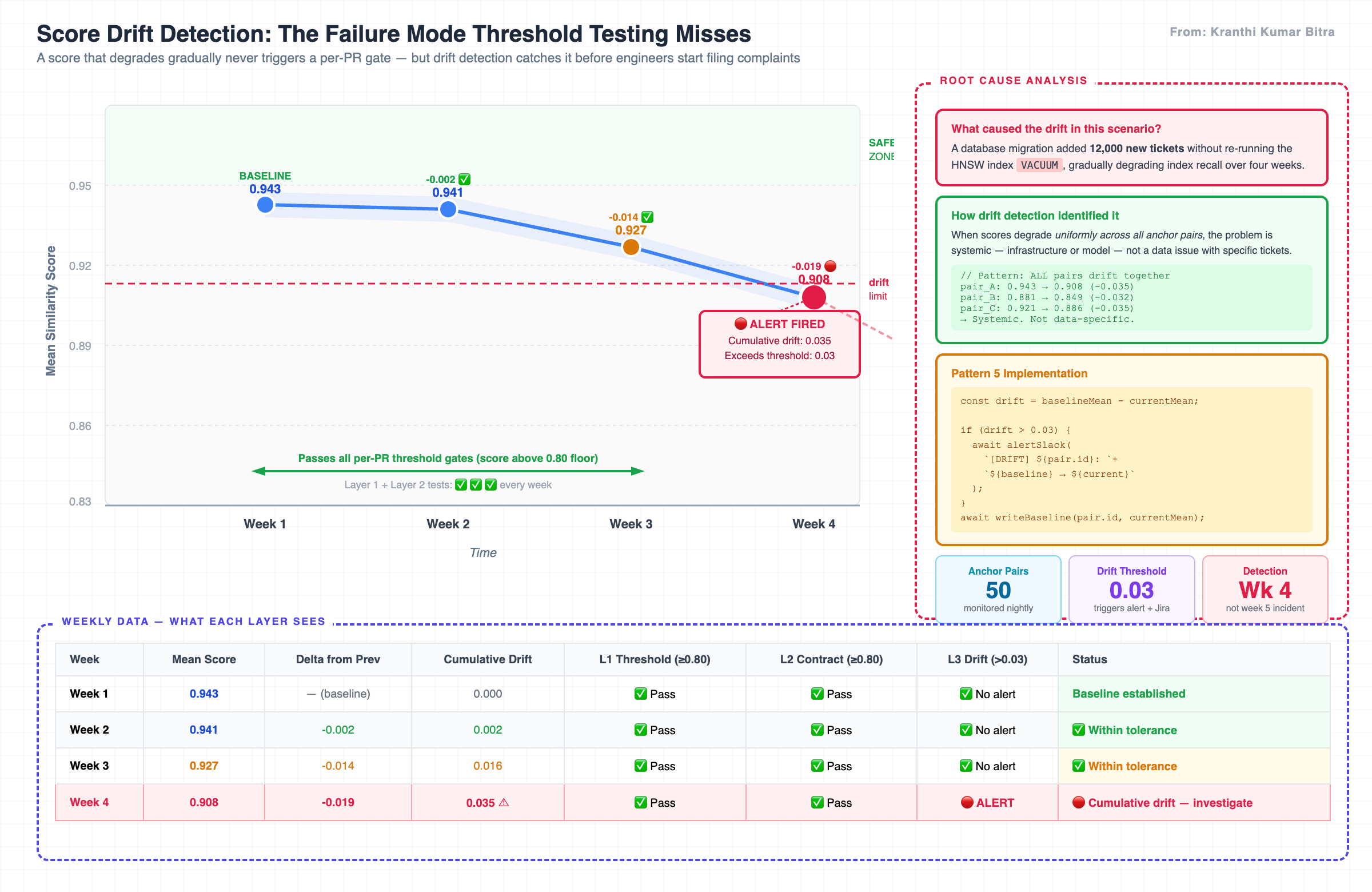
Gradual drift is invisible to threshold-based monitoring. A score that moves from 0.943 to 0.908 over four weeks never breaches a single per-PR gate — until the fifth week when engineers start filing complaints.
In this scenario, Layer 1 and Layer 2 tests passed every week. The threshold was never breached in isolation. But cumulatively, the system had degraded significantly — caused, in this case, by a database migration that added twelve thousand new tickets without re-running the HNSW index VACUUM, gradually degrading index recall.
The diagnostic signal that drift detection provides: When scores degrade uniformly across all anchor pairs, the problem is systemic — infrastructure or model — not a data issue with specific tickets. This distinction directs the investigation to the right team immediately, rather than starting a week-long ticket triage.
Without drift detection, this scenario produces a production incident in week five when engineers start noticing that obvious duplicates are not being flagged. With drift detection, the alert fires in week four with the root cause already implicit in the metric pattern.
The Vector Database: Where Evaluation Meets Infrastructure
One dimension of evaluation that is frequently overlooked is the quality of the vector store itself. The HNSW index in pgvector is not a passive store — it is an active approximation algorithm whose recall accuracy depends on its configuration, its maintenance, and the volume of data it indexes.
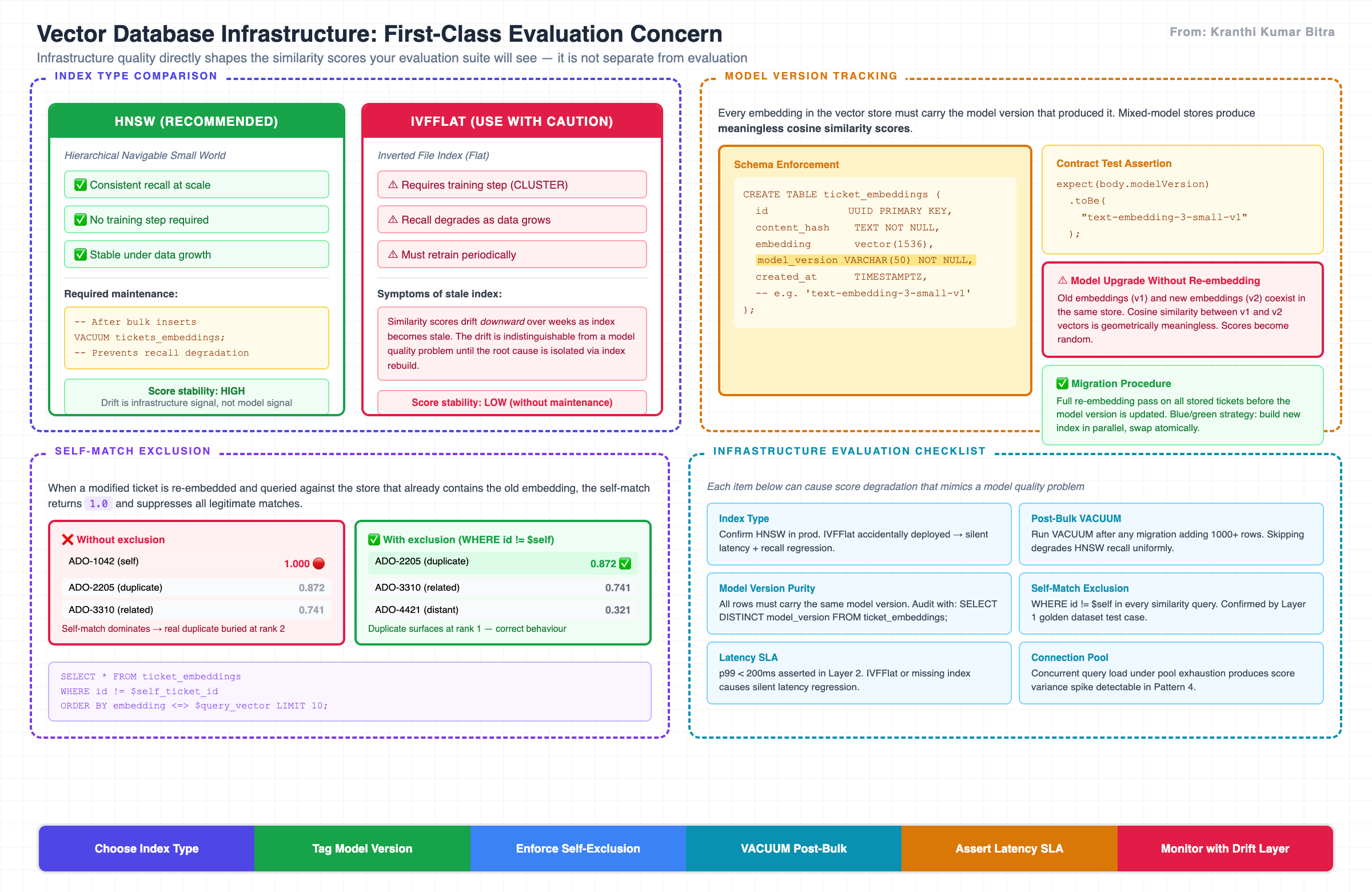
The choice between HNSW and IVFFlat, and the maintenance of whichever index is chosen, directly affects the scores your evaluation suite will see. Infrastructure is not separate from evaluation — it is part of it.
Three infrastructure-level properties must be part of the evaluation strategy:
Index type. HNSW provides consistent recall at scale without requiring a training step. IVFFlat degrades as data grows and requires periodic retraining (CLUSTER). If an IVFFlat index is deployed without maintenance, scores will drift downward as the index becomes stale — and the drift will look identical to a model quality problem until the root cause is isolated.
-- Confirm your production index type
SELECT indexname, indexdef
FROM pg_indexes
WHERE tablename = 'ticket_embeddings';
-- Expect: USING hnsw (embedding vector_cosine_ops)
Model version tracking. Every embedding in the vector store must be tagged with the model version that produced it. If a mix of embedding models exists in the store — which happens whenever a model is upgraded without a full re-embedding run — cosine similarity comparisons between embeddings from different models produce meaningless scores.
-- Schema enforcement
model_version VARCHAR(50) NOT NULL -- e.g. 'text-embedding-3-small-v1'
// Contract test assertion — catches accidental upgrades
expect(body.modelVersion).toBe("text-embedding-3-small-v1");
-- Audit for mixed-model contamination
SELECT model_version, COUNT(*)
FROM ticket_embeddings
GROUP BY model_version;
-- Should return exactly one row
Self-match exclusion. When a new ticket is embedded and queried against the store, if that ticket was already stored (re-embedding a modified ticket, for example), it must be excluded from results. A self-match score of 1.0 will dominate results and suppress legitimate matches.
-- Every similarity query must include this filter
SELECT * FROM ticket_embeddings
WHERE id != $self_ticket_id
ORDER BY embedding <=> $query_vector LIMIT 10;
Anti-Patterns That Will Undermine Your Evaluation
After all of the above, five failure modes are worth naming explicitly because they appear consistently across AI projects:
1. Asserting exact scores. expect(score).toBe(0.87) will be the most brittle test in your suite and will fail first on any infrastructure change, model update, or index maintenance event. The fix is always a band assertion.
2. LLM-generated golden datasets. Asking a model to generate the expected similarity scores for your golden dataset is self-validation, not evaluation. The model will confirm its own outputs. Human curation is non-negotiable.
3. Same judge and generator. If your faithfulness evaluation uses the same model that generated the answer, you will get systematically inflated faithfulness scores. The judge must be a different, ideally stronger, model.
4. Happy-path-only test cases. A golden dataset composed entirely of known high-similarity pairs tells you that the system works when it should work. It tells you nothing about whether it fires when it should not — the false positive problem that erodes engineer trust in duplicate detection. True negatives, adversarial pairs, and edge cases are mandatory categories.
5. No latency assertion. Vector queries have infrastructure dependencies — index type, index freshness, concurrent query load — that can cause silent latency regression. If your contract test does not assert that the response arrived within the SLA, an IVFFlat index accidentally deployed in place of HNSW will go undetected until production engineers start complaining.
Implementation Checklist: Getting Started
The following checklist represents the minimum viable evaluation infrastructure for a production similarity service. It is intentionally ordered by the sequence in which teams typically encounter each problem.
Phase 1 — Before first production deployment
- Define and document score band thresholds (HIGH / MEDIUM / LOW / TRUE NEG) in a shared spec
- Build golden dataset: minimum 20 pairs per band category, human-annotated from real data
- Layer 1 (Vitest) running on every PR, blocking merge on failure
- Layer 2 (Playwright) running on every deploy, asserting schema + score bounds + latency SLA + modelVersion
Phase 2 — First week in production
- Establish Layer 3 baseline: record nightly mean scores for 50 anchor pairs on day 1
- Configure drift alerting: Slack channel + auto-Jira on drift > 0.03
- Confirm HNSW (not IVFFlat) in production index
- Confirm
model_versioncolumn populated for all rows; run audit query
Phase 3 — Ongoing
- Add new failure patterns discovered in production to golden dataset within one sprint
- Review and re-calibrate band thresholds after any embedding model upgrade
- Run Layer 4 E2E before every major release
- Run VACUUM on ticket_embeddings after any bulk import exceeding 1,000 rows
- Quarterly: run RAGAS baseline against production traffic sample; review faithfulness trend
Closing: Evaluation Is Not a Phase
The most significant shift that evaluation engineering represents is a temporal one. In conventional software development, testing is a phase — it happens after building, before release. In AI systems, evaluation is continuous. The model you tested last week is effectively a different model if the index has grown, the embedding model has been updated, or the upstream data has changed in ways that shift the semantic distribution.
The practical implication is that the nightly drift detection pipeline is not a safety net — it is the primary monitoring system. The per-PR golden regression and the per-deploy API contract test are the fast feedback loops. But the signal that tells you whether the system is healthy over time comes from the scores you are measuring every night against baselines you established at go-live.
Design for that. Instrument for that. And treat any unexplained score movement — however small — as a signal worth investigating before it becomes the incident you did not see coming.
If you are operating a production AI system and you do not have a nightly drift detection pipeline, you have a monitoring blind spot. Everything else in this post is context for understanding why that blind spot exists and what to do about it.
Reference: Tooling Stack
| Layer | Purpose | Primary Tool | Language |
|---|---|---|---|
| L1 — Unit regression | Golden dataset assertion | Vitest | TypeScript |
| L1 — Unit regression | Golden dataset assertion | pytest | Python |
| L2 — Contract | API contract + RAGAS bridging | Playwright APIRequestContext | TypeScript |
| L3 — Drift | Nightly score monitoring | Custom cron + Slack API | TypeScript / Python |
| L4 — E2E | Full journey | Playwright (UI + API) | TypeScript |
| RAG eval | Context relevance + faithfulness | RAGAS | Python |
| Faithfulness judge | Hallucination gate | DeepEval + GPT-4o / Claude Opus | Python |
| Vector store | Embedding storage + HNSW index | pgvector (PostgreSQL) | SQL |