
Claude Managed Agents: What a Managed Execution Layer Actually Changes for Engineering Teams
Most teams are still treating agent infrastructure as a build problem. It is an abstraction problem. And the abstraction just landed.

The Infrastructure Problem Nobody Talks About
There is a predictable arc to how engineering teams first encounter production agent failures. They build an impressive demo. They connect the agent to real tools. They test it thoroughly in staging. Then they ship it, and within the first week, something happens that none of their tests anticipated.
The agent loses track of what it was doing mid-task. A container running its execution environment goes unresponsive, and the session is simply gone. A long-running workflow exceeds the model’s context window, and the agent either truncates its understanding of earlier steps or halts entirely. Credentials get exposed in ways the team did not anticipate because they stored them in the same environment where generated code runs. A network disruption drops the agent into an indeterminate state that requires a human to diagnose and restart.
None of these failures are model failures. None of them are prompt engineering problems. They are infrastructure problems: the scaffolding that wraps the model, manages its execution environment, persists its state, handles its credentials, and recovers from failures. Building that scaffolding correctly takes months. Most teams do not have months, and most teams do not have the specialist knowledge to build it well even when they do have time.
This is the problem that a managed execution layer for agents solves. And it is a more fundamental shift than most commentary on the topic has recognized.
What Agent Scaffolding Actually Requires
Before examining what a managed execution layer provides, it is worth being precise about what teams have been building from scratch. The gap is larger than the typical “deployment is hard” framing suggests.
A production agent is not a model call inside a loop. It is a system with at least six distinct infrastructure concerns, each of which requires explicit engineering decisions.
Session state management is the requirement to persist everything that happened in an agent’s execution across the lifetime of a task. In a stateless environment, the agent starts from nothing on every request. In a production agent, the full history of actions taken, tool results received, errors encountered, and decisions made must be available to the agent at every step. When a container restarts, or when the agent is handed off to a different process, that history must be recoverable. Building this correctly requires an append-only log architecture that is durable, queryable, and independent of the execution environment.
The context window problem is a deeper version of session state. Language models have finite context windows. Long-running workflows exceed them. The conventional responses to this are compaction, summarization, and selective trimming. All three are irreversible: once you decide which parts of the context to discard, that decision cannot be undone if a later step turns out to need what you discarded. Building a system that handles context overflow gracefully, without irreversible loss, requires treating the session log as a durable external object that the agent can selectively query rather than a window the agent passively receives.
Secure execution sandboxing is the requirement that code generated by the agent runs in an environment that cannot access the credentials, secrets, or privileged configuration of the harness around it. This sounds straightforward but is easy to get wrong. The common failure mode is storing credentials in the same container environment where generated code executes. A prompt injection attack that convinces the agent to read its own environment variables now has access to everything the agent has been given permission to use. Structural credential isolation requires that the execution sandbox and the credential store are entirely separate, with the harness acting as a proxy that the sandbox calls through, never accessing credentials directly.
Harness durability is the requirement that the agent harness itself can fail without losing the session. If the harness is a stateful process, a crash means losing the agent’s current state. Making the harness stateless requires that all state lives in the session log and that a new harness instance can resume from the last event with no coordination overhead. This is a specific architectural pattern, not a default.
Tool and MCP integration is the connection surface between the agent and the external world. Every tool the agent can call is a potential failure point. At scale, agents make thousands of tool calls across dozens of different external services. Managing authentication, retry logic, rate limiting, and error propagation consistently across all of them requires a dedicated integration layer.
Observability is the ability to understand what the agent did, why, and what the consequences were. Agents that make decisions autonomously across long workflows require tracing that captures not just API calls but the full reasoning sequence: what context the agent had, what it decided to do, what the tool returned, and what the agent concluded.
Each of these concerns demands explicit engineering work. Teams building agents from scratch are building all six simultaneously, usually while also trying to ship product features. The failure rate is high, and the failures are often invisible until a production incident surfaces them.

The Meta-Harness Architecture
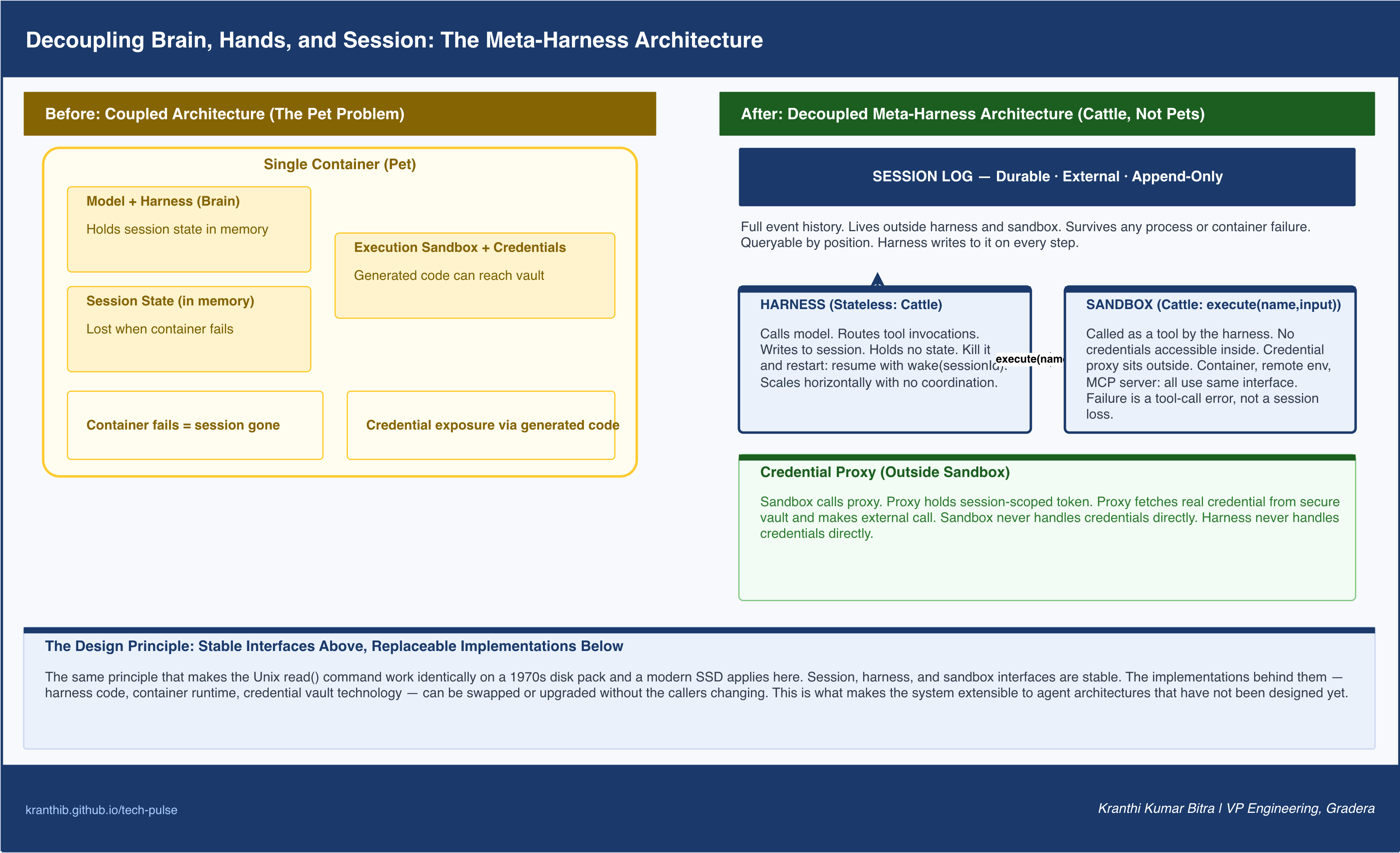
The architectural insight at the center of a managed execution layer is the separation of three things that conventional agent architectures couple together: the brain, the hands, and the session.
In a conventional agent implementation, all three live in the same container. The model and its harness run in the same environment as the execution sandbox where code runs. The session state is held in memory in that same container. Credentials may be present in environment variables that the execution environment can access.
This coupling creates the pet problem. A pet is an infrastructure unit that you cannot afford to lose because it holds unique, unreproduceable state. When everything lives together in one container, that container becomes a pet. If it fails, the session is gone. If it becomes unresponsive, an engineer must debug it directly. If you want to connect the agent to infrastructure in a different network, the agent’s container must move there too, or complex peering arrangements must be set up.
The solution is to decouple all three components and define stable interfaces between them.
The session becomes an append-only, durable log of everything that happened: every model call, every tool invocation, every result, every error. The session is not stored in the harness or the sandbox. It is stored independently, outside both. The harness writes to it continuously. When the harness fails, a new harness instance can be started and given the session ID. It fetches the full event log, resumes from the last event, and continues without loss. The session outlasts any individual process or container.
The harness becomes stateless. It is the orchestration loop: call the model, receive a tool invocation, route the tool call to the appropriate execution environment, receive the result, write it to the session, call the model again. Because the session holds all state, the harness holds none. It can be killed and restarted without consequence. Any failure the harness encounters, including failures in the sandboxes it manages, surfaces as a tool-call error that gets passed back to the model like any other error response.
The sandbox becomes cattle. In the pet-versus-cattle distinction, cattle are interchangeable execution units. If one dies, you provision another from a standard recipe. The sandbox is now just one of many tools the harness can call, addressed through a uniform interface: a name goes in, a result string comes out. The harness has no assumption about whether the sandbox is a local container, a remote container, a cloud function, or any other execution environment. It just calls the interface.
This architecture produces a system of the form that the underlying operating systems abstraction has always produced: stable interfaces above, replaceable implementations below. The interfaces define what callers need to know. The implementations can be swapped, upgraded, or replaced without the callers changing.
The Context Window Is Not the Session
One of the most consequential clarifications in the meta-harness model is the distinction between the session log and the model’s context window. These are not the same thing, and conflating them produces the most common category of long-running agent failure.
The context window is what the model sees at each call. It is finite. It is constructed fresh for each model invocation by the harness, which selects from the session log what to include. The context window is ephemeral. The session log is permanent.
This distinction matters because it changes what “losing context” means. In a conventional agent, when the context window overflows, the team must make irreversible choices: summarize old messages, drop tool results, trim thinking blocks. Whatever is discarded is gone. If a later step needed something that was discarded, the agent proceeds without it and often produces wrong or inconsistent output.
In the meta-harness model, the session log is always complete. Nothing is discarded from the log. The harness can construct different views of the log for different model calls: a full view, a windowed view starting from a specific event, a view that excludes verbose tool results but retains their summaries, a view reordered for cache efficiency. These are lossless transformations of a complete record, not irreversible discards of a partial one.
The interface that enables this is simple. The harness calls a session query function with positional parameters: give me events from position N to position M. This allows the harness to resume from where it last stopped, rewind a few events before a specific decision to understand its context, or selectively re-read sections before high-stakes actions. The model always receives a correctly sized context window. The session log always contains the full truth.
This is why session management and context engineering, while related, require separate architectural treatment. Context engineering is the problem of what to show the model in any given call. Session management is the problem of what to durably store across the full lifetime of a task. Solving one does not solve the other.

Credential Isolation: Why Structure Matters More Than Policy
Security in agent systems is a subject where policy-level thinking is frequently applied to what is actually a structural problem. Teams write policies about which tools agents can access, which environments they can touch, and what data they can read. Then they deploy agents with credentials stored in the same environment where generated code runs, and the policies become irrelevant the moment an attacker can convince the agent to read its environment variables.
The structural fix to credential exposure is to ensure that the sandbox where generated code executes can never reach the credential store where the harness holds its authentication tokens. This requires a specific separation of trust domains.
The pattern that achieves this is proxy-based credential management. For external services accessed via standard protocols, the execution sandbox is given no credentials at all. It calls a proxy. The proxy holds the session-scoped authentication token. The proxy fetches the actual service credential from a secure vault and makes the call to the external service. The sandbox never sees the credential. The harness never sees the credential. If a prompt injection convinces the agent to exfiltrate its environment, there is nothing to exfiltrate.
For version control and similar systems that require local authentication, a different pattern applies: the credential is used to initialize the local repository during sandbox setup, wired into the local configuration in a way that makes subsequent authenticated calls work without re-presenting the credential. The agent pushes and pulls normally. It never handles the token that authorized those operations.
This structural isolation is not achievable by narrowing credential scope alone. Narrowly scoped credentials in the same environment as generated code are still accessible. Credentials that physically cannot be reached from the generated code execution environment are structurally protected. The distinction between these two is the difference between a policy control and a structural control, and structural controls are the ones that hold under adversarial conditions.
Scaling Patterns: Many Brains, Many Hands
One of the practical consequences of the decoupled architecture is that scaling becomes straightforward in ways it was not when everything ran in a single container.
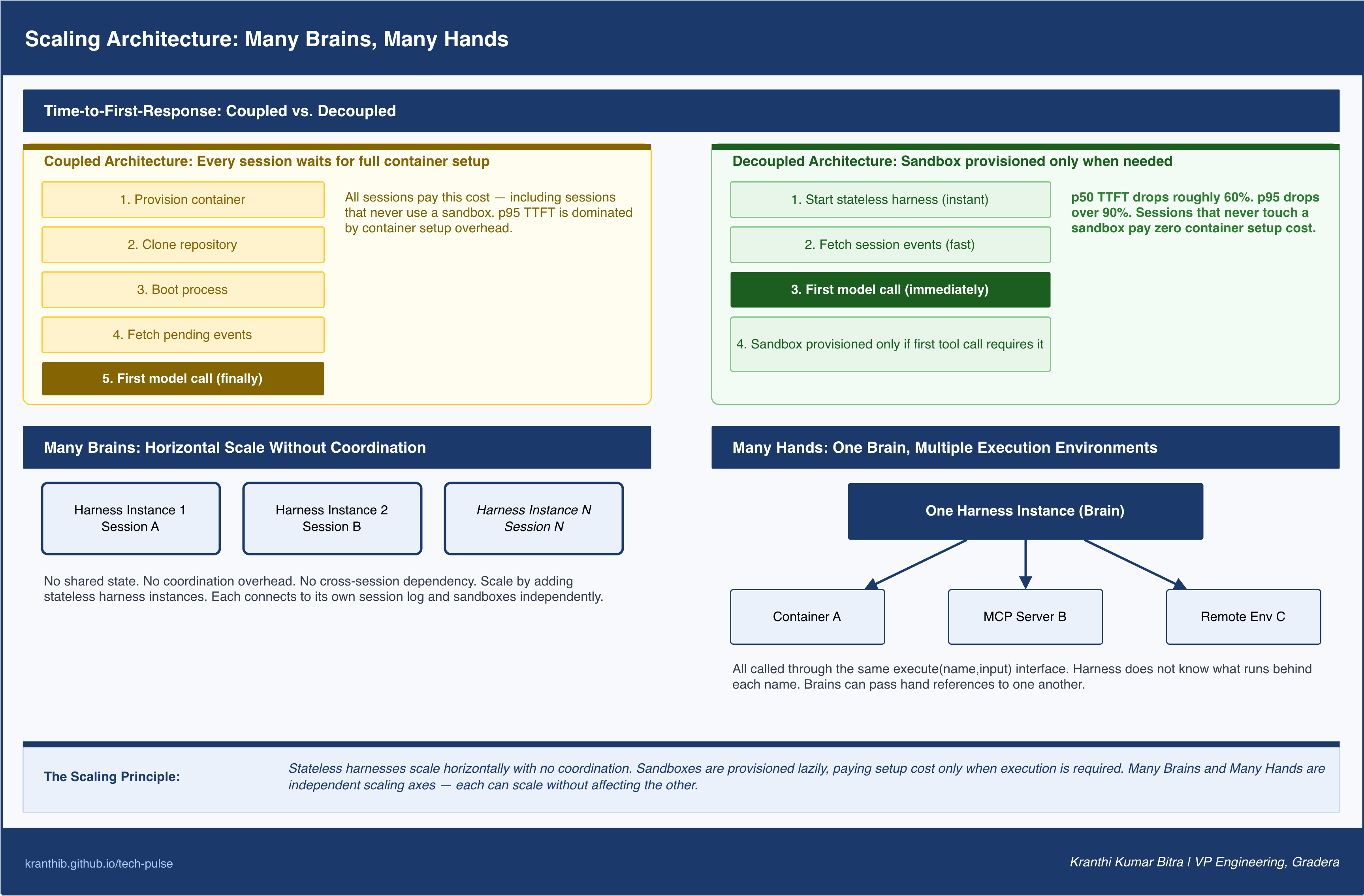
In the coupled architecture, one agent session required one container. Before any agent work could begin, that container had to be provisioned, the repository had to be cloned, the process had to start, and pending events had to be fetched from the session log. All of that setup time was dead time from the user’s perspective. Every session paid it, even sessions that would never touch the sandbox at all.
In the decoupled architecture, the harness is stateless and starts instantly. It begins fetching events from the session log and calling the model as soon as it has the session ID. Sandbox containers are provisioned only if the agent’s task actually requires one, and only when the agent makes its first tool call that requires one. Sessions that perform reasoning and API calls without needing a local execution environment never pay the container setup cost.
The practical result is dramatic reduction in time to first response. Sessions that previously waited for full container initialization now begin producing output immediately. The latency the user experiences, the gap between submitting a task and receiving the first substantive response, collapses for the majority of workloads.
Many-brain scaling works the same way. Running multiple agent sessions simultaneously means running multiple stateless harness instances. There is no shared state, no coordination overhead, no cross-session dependency. Each harness connects to its session log and its sandboxes through the defined interfaces and operates independently.
Many-hand scaling, where a single agent session manages multiple execution environments simultaneously, is the more complex case. It requires the model to reason about multiple execution environments and direct work to the appropriate one. Earlier models struggled with this cognitive task. As model intelligence has increased, the single-container constraint has inverted: the single container has become the limitation, not the model’s capability. The interface that allows multiple sandboxes is the same as the interface that allows one: a name goes in, a result string comes out. The harness routes to whichever sandbox matches the name. The model decides which sandbox to use.
What This Changes for Engineering Leaders
The arrival of a managed execution layer changes several calculations that engineering leaders have been making about agent deployment.
The build-versus-buy decision shifts. For the past two years, the build-versus-buy calculation on agent infrastructure has leaned heavily toward build, because the available managed offerings did not provide sufficient control over execution semantics, session management, or security architecture. A managed layer that exposes stable, well-defined interfaces for session, harness, and sandbox changes that calculation. Teams can now focus their engineering capacity on agent logic, tool integrations, and evaluation rather than on the infrastructure that runs agents.
The time-to-production estimate changes. Production-grade agent infrastructure built from scratch takes months: designing the session persistence layer, building the harness recovery mechanism, implementing credential isolation, instrumenting observability. A managed layer that handles these concerns reduces that timeline to days or weeks. This is not a minor optimization. For organizations that have been deferring agent deployment because the infrastructure investment was too large, it removes the primary blocker.
The vendor concentration question becomes relevant. Running agent workloads on managed infrastructure increases dependence on the platform provider. Workflows and operational state become embedded in a specific platform’s abstractions. The switching cost is real: migrating a production agent from a managed platform to a self-hosted infrastructure requires rebuilding the session layer, the harness recovery mechanism, and the credential isolation architecture from scratch. Engineering leaders should evaluate the portability of their agent definitions and the extent to which their tool integrations are standard-interface-based before committing production workloads to a managed platform.
The infrastructure skill gap is no longer the bottleneck. The teams most capable of building effective agents are not always the teams with the deepest infrastructure expertise. Product engineers who understand the domain deeply but lack distributed systems experience have been unable to ship agents to production without significant infrastructure investment. A managed layer that abstracts session management, harness recovery, and secure sandboxing allows domain expertise to drive agent development rather than infrastructure expertise.
The Decision Framework: When to Use a Managed Layer
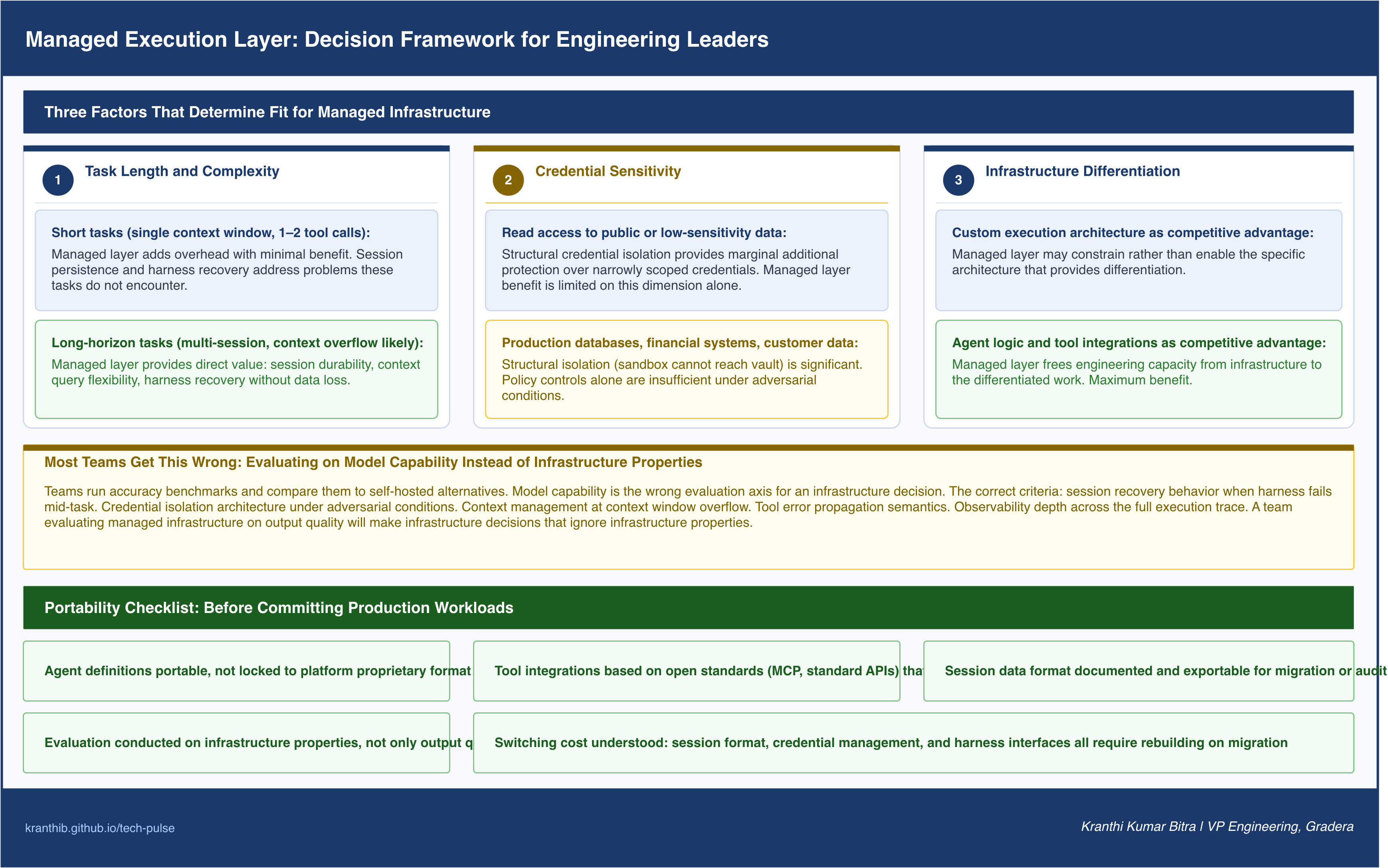
Not every agent workload belongs on a managed execution layer. The decision depends on three factors: the length and complexity of the task, the sensitivity of the credentials involved, and the degree to which custom infrastructure provides competitive differentiation.
Task length and complexity is the clearest signal. Short, stateless tasks that complete in a single context window, make one or two tool calls, and have straightforward success criteria do not benefit much from a managed layer. The session persistence, harness recovery, and context management capabilities of a managed layer address problems that short tasks do not encounter. Long-horizon tasks that span multiple sessions, require complex tool orchestration, or exceed a single context window benefit substantially.
Credential sensitivity is the second signal. Workloads that require the agent to operate with high-privilege credentials benefit from structural credential isolation. If the agent has read access to a public dataset, the structural separation of credential storage from execution environment provides marginal additional protection. If the agent operates with access to production databases, financial systems, or customer data, the structural isolation is significant.
Infrastructure differentiation is the third signal. Teams building agents where the agent logic and tool integrations are the source of competitive differentiation gain the most from managed infrastructure. Teams whose competitive advantage lies in a specific execution architecture, a custom observability layer, or proprietary session management may find that a managed layer constrains rather than enables their approach.
The honest version of this framework: most enterprise agent workloads fit the profile for managed infrastructure. Long tasks, sensitive credentials, and agent logic differentiation are the most common combination in production enterprise deployments.
What Most Teams Get Wrong
The most common mistake I see teams make when evaluating managed agent platforms is treating the evaluation as a model capability comparison. They test whether the agent produces correct outputs. They measure accuracy on representative tasks. They compare cost per output across alternatives.
These are the wrong evaluation criteria for a managed infrastructure decision.
The correct evaluation criteria are infrastructure properties: session recovery behavior when the harness fails mid-task, credential isolation architecture under adversarial conditions, context management behavior at the boundary where task length exceeds the context window, tool error propagation semantics, and observability depth across the full agent execution trace.
A team that evaluates managed infrastructure on model capability will make the right decision for the wrong reasons in some cases and the wrong decision entirely in others. A team that evaluates on infrastructure properties will understand what they are buying and what they are giving up.
The second most common mistake is underestimating the migration cost after the initial deployment. Agent workflows that run on managed infrastructure embed operational state in the platform’s session abstraction. Tool integrations authenticate through the platform’s credential proxy. Harness behavior is governed by the platform’s recovery semantics. When a team later wants to move to a different platform or self-host, the session data format, the credential management approach, and the harness interface all require rebuilding. This is not a reason to avoid managed infrastructure. It is a reason to evaluate the portability of your agent definitions and tool interfaces before committing, and to build toward open standards for inter-agent communication wherever possible.
Where This Is Heading
Managed agent infrastructure is the first significant shift in how agent systems are deployed since the initial frameworks were introduced. But it is not the final shift.
The next generation of the problem is standardisation. Right now, agent sessions defined on one managed platform are not portable to another. The interfaces between brain, hands, and session are well-designed within each platform but are not interoperable across platforms. The same dynamics that drove standardisation in cloud infrastructure, containerization, and API protocols will eventually drive standardisation in agent execution interfaces. The teams and platforms that define those standards will have outsized influence over the architecture of the next generation of agent systems.
The other trajectory to watch is the relationship between managed infrastructure and model capability. The meta-harness insight is that harnesses encode assumptions about what the model cannot do. Those assumptions go stale as models improve. A harness behavior that was necessary for a less capable model becomes dead weight for a more capable one. Managed infrastructure that is designed to evolve its harness implementation while keeping interfaces stable is positioned to capture capability improvements automatically. Teams that build custom harnesses will periodically need to revisit and refactor those harnesses as model capabilities change.
The engineering leaders building agents today should evaluate managed infrastructure not just on its current capabilities but on the architecture of its abstraction layer. An abstraction layer designed for “programs as yet unthought of”, interfaces that are stable as implementations change, is worth more than a feature list. It is the difference between infrastructure that requires constant maintenance as the underlying technology evolves and infrastructure that absorbs that evolution by design.
Conclusion
The infrastructure challenge in production agent deployment has been the silent bottleneck for two years. Teams have been building session persistence, harness recovery, credential isolation, and context management from scratch, repeatedly, with variable quality and substantial time investment.
A managed execution layer that separates session, harness, and sandbox into independently stable, replaceable components changes the build calculus fundamentally. It removes the infrastructure expertise requirement from agent deployment and shifts the competitive differentiation to where it belongs: agent logic, tool integrations, and evaluation.
The decision framework is straightforward: long-horizon tasks, sensitive credentials, and agent-logic-driven differentiation point toward managed infrastructure. The evaluation criteria are infrastructure properties, not model capabilities. And the portability of your agent definitions and tool interfaces deserves explicit assessment before committing production workloads to any specific platform.
The post-mortem from every production agent failure tells the same story. The model did not fail. The infrastructure around the model failed. Managed execution layers are the engineering discipline’s answer to that pattern.