
Multi-Agent Orchestration Patterns: Why Your System Fails at the Handoff, Not the Agent
The uncomfortable truth about production multi-agent systems, and the contract design discipline that fixes it.

The Incident That Changed How I Think About Orchestration
Eighteen months ago, a team I was working with shipped a multi-agent system they were genuinely proud of. Four specialized agents (one for document parsing, one for entity extraction, one for compliance checking, one for report generation) connected through an orchestration layer that had taken three months to build. In staging, it was elegant. Reliable. Fast.
In production, it fell apart on day three.
The document parser started returning partially structured output when it hit malformed PDFs, output that was technically valid JSON but semantically incomplete. The entity extractor received that partial output, processed it without complaint, and passed its own incomplete result downstream. The compliance checker ran its logic on a data model that was missing two required fields. It did not error. It silently skipped the checks that depended on those fields. The report generator produced a clean, well-formatted output that was factually wrong in three sections.
Nobody noticed for eleven days.
When we did the post-mortem, the failure was not in any individual agent. Every agent had done exactly what it was built to do. The failure was in the orchestration layer: specifically in the complete absence of contracts between agents. Nobody had defined what a valid output from the parser looked like. Nobody had specified what the extractor was allowed to assume about its inputs. Nobody had described what the compliance checker should do when required fields were absent. The orchestration layer treated handoffs as routing events, not as moments requiring contract enforcement.
That incident reframed how I think about multi-agent architecture. The agent logic is the easy part. The orchestration contracts are the hard part. Most teams get this exactly backwards.
Why Single-Agent Architectures Break at Scale
Before addressing multi-agent orchestration, it is worth being precise about why single-agent architectures force the transition in the first place. Teams often move to multi-agent systems because they have hit the ceiling on what a single agent can do reliably, but the ceiling is rarely where they think it is.
The three real limits of single-agent architectures are domain overload, context saturation, and sequential bottleneck.
Domain overload occurs when a single agent is asked to hold too many specialized roles simultaneously. An agent handling document parsing, entity recognition, regulatory lookup, and report formatting is not specializing, it is generalizing. Generalization works fine in low-stakes environments where errors are acceptable. In production environments where downstream decisions depend on precision, generalization is a reliability tax you pay on every call.
Context saturation is more technically grounded. Language model context windows are finite, and multi-step tasks consume them faster than single interactions. When an agent must maintain the full context of a complex, branching task, it is simultaneously the navigator, the executor, and the memory manager. At the point where context gets trimmed, which every production system must do, the quality of the agent’s work degrades unpredictably, because you cannot always know which context was critical.
Sequential bottleneck is the throughput problem. A single agent processing a complex workflow serially cannot parallelize any step. If step four depends on step three but step five is independent of both, the single-agent architecture cannot exploit that independence. Multi-agent architectures can.
The transition to multi-agent systems is not a response to AI limitations. It is a response to the same engineering principles that drive microservices adoption in conventional software: separation of concerns, independent scalability, and fault isolation. The problem is that teams apply microservices thinking to agent logic and then treat orchestration as an afterthought: exactly as early microservices teams did with service meshes.
Figure 1. How domain overload, context window saturation, and sequential throughput cap single-agent systems—and how multi-agent separation parallels microservices-style boundaries.

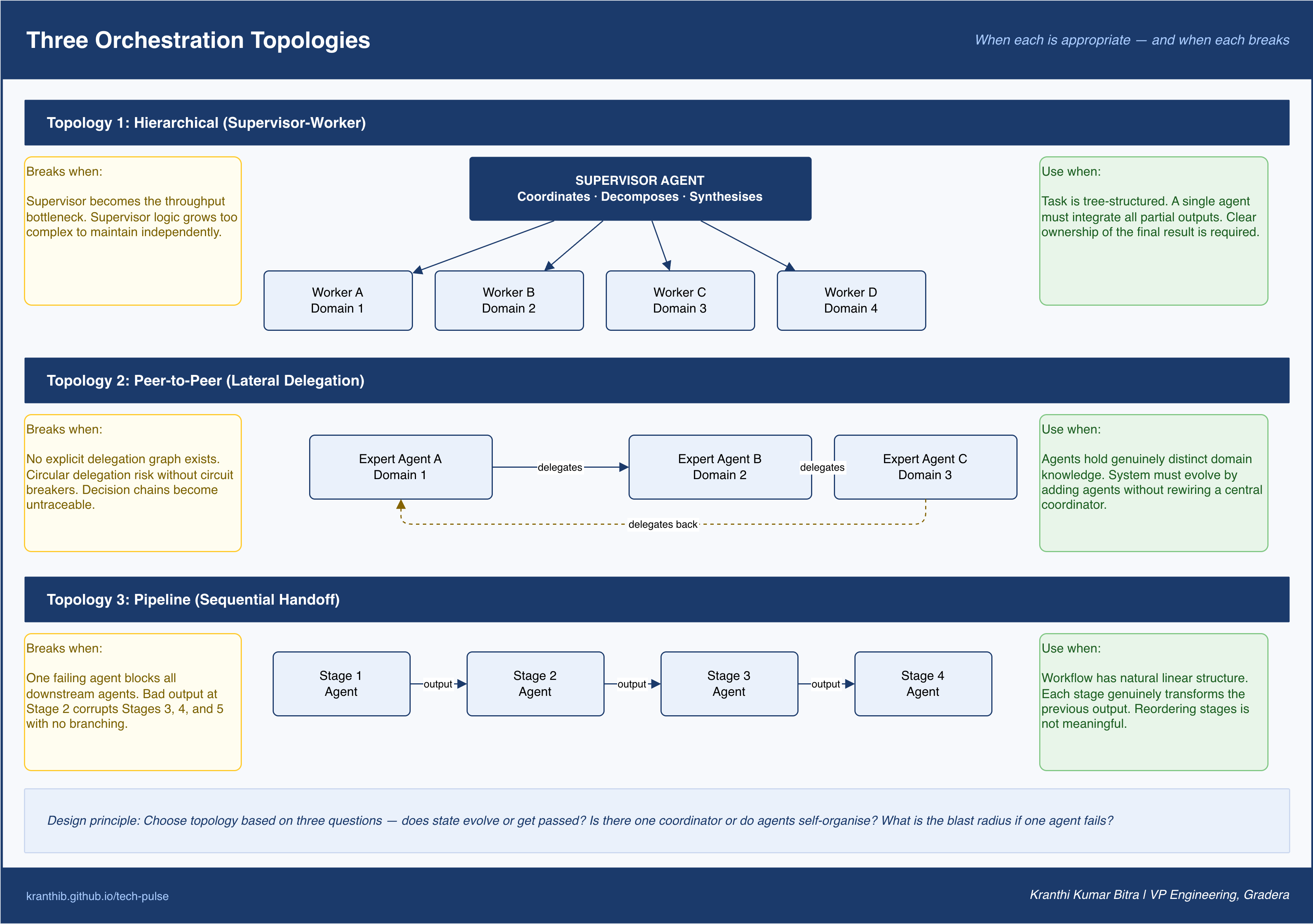
The Three Orchestration Topologies
Multi-agent systems are not monolithic. The way agents relate to one another, who coordinates whom, in what direction, with what authority, defines the topology. There are three fundamental topologies, and choosing the wrong one for a given problem is one of the most expensive architectural mistakes a team can make.
Hierarchical: Supervisor-Worker
In a hierarchical topology, a supervisor agent manages a set of worker agents. The supervisor receives the top-level goal, decomposes it into subtasks, delegates each subtask to the appropriate worker, and synthesizes the results. Workers operate within a defined scope and do not communicate laterally, all coordination passes through the supervisor.
This topology is the right choice when task decomposition is inherently tree-structured, when the quality of the final output depends on integrated synthesis of all worker outputs, and when there is a clear “owner” of the task who can evaluate partial results and redirect workers if needed.
It breaks when the supervisor becomes a bottleneck. In high-throughput systems where workers operate faster than the supervisor can process their outputs, the hierarchical topology creates a coordination ceiling. It also breaks when supervisor logic grows so complex that it becomes a black box: at which point the supposed clarity of central coordination becomes its own failure mode.
Peer-to-Peer: Lateral Delegation
In a peer-to-peer topology, agents coordinate directly with one another based on capability rather than hierarchy. Agent A encounters a task that falls within Agent B’s domain and delegates directly to B, no central coordinator involved. Agents self-organize around their specializations.
This topology works well in expert networks, systems where different agents hold genuinely distinct domain knowledge and can negotiate which agent handles which aspect of a complex problem. It is also the natural topology for systems that need to evolve dynamically, where adding a new capability means adding a new agent without rewiring a central orchestrator.
The failure mode is emergent complexity. Without a central coordinator, it is difficult to trace decision chains when something goes wrong. Circular delegation, where Agent A delegates to Agent B, which delegates back to Agent A, becomes a real risk if agents are not designed with explicit self-knowledge about their delegation authority. Peer-to-peer topologies require disciplined contract design precisely because there is no central authority to catch bad handoffs.
Pipeline: Sequential Handoff
In a pipeline topology, agents operate in a defined sequence. Agent 1 processes input and passes output to Agent 2. Agent 2 processes and passes to Agent 3. The output of one agent is the sole input of the next.
This is the most familiar topology for engineers coming from data pipeline backgrounds. It is straightforward to reason about, straightforward to debug, and straightforward to extend. It is appropriate when the workflow has a natural linear structure, where each stage genuinely transforms the output of the previous stage in a way that cannot be reordered or parallelized.
The pipeline topology’s weakness is brittleness. One failing agent blocks every downstream agent. Error propagation is linear and fast, a bad output in step two corrupts everything in steps three, four, and five. Pipeline systems require particularly rigorous contract definition at every stage boundary, because there is no branching logic to catch or route around bad outputs.
Figure 2. The three coordination patterns—hierarchical (supervisor–worker), peer-to-peer, and pipeline—and when each topology tends to succeed or break down in production.
Task Decomposition as a Discipline
One of the most underestimated skills in multi-agent system design is task decomposition, the act of breaking a high-level goal into agent-sized units of work. Most teams decompose tasks informally, during implementation, guided by intuition about what seems like a reasonable chunk of work for a single agent. This is a mistake.
Decomposition done informally tends to produce agent boundaries that map to implementation convenience rather than semantic coherence. The result is agents that are either too large (handling multiple distinct concerns that should be separated) or too small (producing outputs so granular that reassembly requires more work than the decomposition saved).
Principled task decomposition starts from three questions.
What is the smallest unit of output that is independently verifiable? An agent should produce an output that can be validated, either by another agent, by a human reviewer, or by a deterministic check, without reference to the agent’s internal reasoning. If the only way to know whether an agent succeeded is to re-run the task, the output boundary is wrong.
What information does the agent need at execution time, and where does that information come from? Every dependency an agent has on external state is a potential failure point. Decomposition should minimize the surface area of state dependencies per agent. An agent that requires seventeen fields from a shared state object to do its job is probably doing too much, or the decomposition boundary is in the wrong place.
What does failure look like, and how should the system respond? This question belongs in decomposition, not in implementation. If the answer to “what happens when this agent fails” is “I’m not sure yet,” the decomposition is not complete.
The goal of decomposition is not just parallelism or specialization, it is producibility of checkpoints. A well-decomposed multi-agent system produces observable, verifiable outputs at every stage boundary. This is what makes debugging tractable in production.
Shared State Management: What Agents Own versus What They Share
State management is where multi-agent systems accumulate the most subtle bugs. The core tension is straightforward: agents need shared context to coordinate effectively, but shared mutable state is a concurrency and consistency problem in any distributed system.
The framing I use is the distinction between owned state, shared state, and passed state.
Owned state is state that belongs to a single agent and is never written by another agent. An agent’s internal scratchpad, its decision history, its current task context, these are owned state. No other agent should write to them. If another agent needs information from an agent’s owned state, it must request it through a defined interface. It does not access the state directly.
Shared state is state that multiple agents read and that some agents write, with defined write authority. A document being processed by a pipeline might be shared state, each agent reads the current version, applies its transformation, and writes an updated version. The key design requirement is that write authority is explicit: for any piece of shared state, exactly one agent (or one agent at a time, via a lock mechanism) has write authority at any given moment. Systems where write authority is implicit or contested produce race conditions that are extremely difficult to diagnose.
Passed state is state that is transferred from one agent to another at a handoff point and then owned by the receiving agent. This is the cleanest form of state management in pipeline topologies, the sending agent produces a well-defined output object, the receiving agent takes ownership of it, and the sending agent’s responsibility ends.
The most common state management failure I have seen is the conflation of shared state and passed state. A team designs what they think is a clean handoff, agent A produces output, agent B receives it, but then adds a “global context” object that both agents read and write without defined authority. The global context is the shared state problem that was supposed to be solved by the handoff abstraction. Every system has one. Finding it and defining write authority rules is non-negotiable work before production.
Figure 3. Owned, shared, and passed state: a concise model for deciding who may read or write what—and why conflating “clean handoffs” with an implicit global context object breaks production systems.

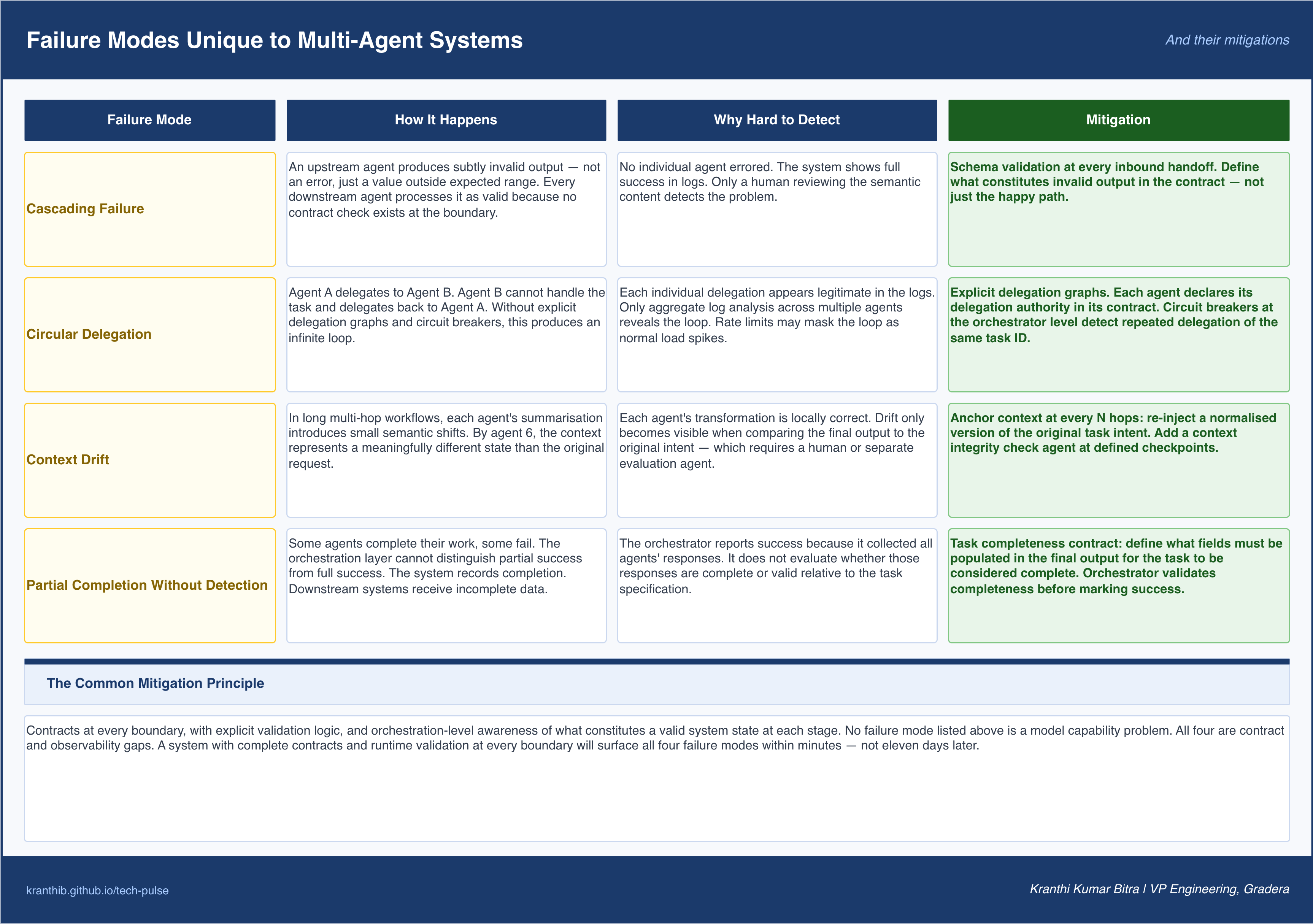
Failure Modes Unique to Multi-Agent Systems
Multi-agent systems do not just fail in the ways that single-agent systems fail. They introduce failure modes that are genuinely novel, modes that emerge from the interactions between agents rather than from the behavior of any individual agent.
Cascading failure is the most common. An upstream agent produces a subtly invalid output, not an error, just a value that is outside the expected range or missing a field. Every downstream agent processes that invalid output as if it were valid, because no contract check exists at the handoff point. The final output is wrong, but no individual agent errored, so no alert fires. The system succeeded in its own eyes. This is the failure mode that took eleven days to detect in the incident I described earlier.
Circular delegation occurs in peer-to-peer topologies when agent A delegates to agent B, which determines it cannot handle the task and delegates back to agent A, which may then delegate to agent B again. Without explicit delegation graphs and circuit breakers, circular delegation produces infinite loops that are both resource-intensive and difficult to detect in logs (each delegation looks legitimate in isolation).
Context drift is a subtler failure. In long-running multi-hop workflows, the context passed between agents accumulates transformations. By the time the sixth agent in a chain receives the context, it may represent a significantly different semantic state than the original request, not because any agent made an error, but because each agent’s summarization, extraction, or transformation introduced small shifts. Context drift is invisible to individual agents and only becomes visible at the level of the final output versus the original intent.
Partial completion without detection occurs when a workflow partially succeeds, some agents complete their work, some fail, but the orchestration layer cannot distinguish partial success from full success. The system records a successful completion. The downstream systems that depend on the output receive incomplete data. This is particularly dangerous in hierarchical topologies where the supervisor collects partial results and synthesizes them without verifying completeness.
The mitigation strategy for each of these failure modes is the same: contracts at every boundary, with explicit validation logic, and orchestration-level awareness of what constitutes a valid state at each stage of the workflow.
Figure 4. Interaction-level failure modes—cascading silent errors, circular delegation, context drift, and partial completion—together with the shared mitigation: explicit contracts and validation at every handoff.
The Contracts-First Design Pattern
This is the reframe that changes how teams approach multi-agent architecture: orchestration is contract design, not routing design.
A router decides where to send something. A contract defines what can be sent, what constitutes a valid receipt, and what happens when either side of the exchange fails to deliver. These are entirely different problems. Most orchestration layers are built as routers. They should be built as contract enforcers.
An agent contract has four components.
Input schema: A precise specification of what the agent accepts, field names, types, required versus optional, valid value ranges, and any semantic constraints that cannot be expressed in a type system. An agent that accepts “a document” is not contracted. An agent that accepts “a JSON object with fields document_id (string, UUID format), content (string, max 50,000 characters), document_type (enum: invoice |
contract | report), and processing_priority (integer, 1-5)” is contracted. |
Output schema: The equivalent specification for what the agent produces. Including not just the structure of successful outputs, but the structure of partial outputs and error outputs. If an agent can produce a “partial success”, some fields populated, others absent. That partial structure must be defined. The contract defines what downstream agents are allowed to assume.
Preconditions: Explicit statements of what must be true in the system state before the agent executes. If Agent C requires that Agent B has completed successfully before running, that is a precondition. If Agent D requires that a configuration object is present in shared state before it can operate, that is a precondition. Preconditions that are implicit become assumptions that become bugs.
Failure handling specification: What the agent does when it cannot produce a valid output. Does it retry? Does it produce a partial output? Does it signal the orchestrator to escalate? The failure handling contract is what prevents cascading failure. An agent without a defined failure handling contract will either silently pass bad output downstream or raise an unhandled exception, neither of which is acceptable in production.
The contracts-first pattern means these four components are defined before any agent logic is written. The contract is the architectural artifact. The agent implementation is constrained by the contract, not the other way around.
This inverts the usual build order. Most teams build agent logic, then wire up the orchestration, then handle errors when they appear in production. Contracts-first teams define the interface surface of the entire system, validate that the interfaces compose correctly, and only then implement the agents that satisfy those interfaces.
The upfront cost is real. Contracts take time to write and require cross-team agreement. The production benefit is also real: a system with explicit contracts at every boundary fails fast, fails visibly, and fails at the boundary where the problem originated, not three agents downstream.
Figure 5. The contracts-first view of orchestration: input and output schemas, preconditions, and failure-handling rules as architectural artifacts that precede agent implementation.

Choosing Your Orchestration Topology: A Three-Question Diagnostic
Before committing to an orchestration topology, three questions narrow the decision space significantly.
Question 1: Do agents need to share evolving state, or pass completed outputs?
If agents must read and write a shared context that evolves across the lifetime of a task, if Agent C needs to see the intermediate work of Agent B, not just its final output, you are dealing with shared evolving state. This points toward peer-to-peer or hierarchical topologies, where coordination of shared state is built into the architecture. If agents only need the completed, validated output of the previous agent, a pipeline topology is appropriate and the shared state problem largely disappears.
Question 2: Is there a single coordinating intelligence, or do agents self-organize by capability?
If there is a natural “owner” of the task, an agent or a process that can evaluate partial results, redirect work, and synthesize the final output: hierarchical is appropriate. The supervisor is that coordinating intelligence. If agents are genuinely independent specialists who determine among themselves who handles what, peer-to-peer is appropriate. The self-organization is the coordination mechanism. If neither of these descriptions fits your system, that is a signal that the decomposition is not complete, not that you need a novel topology.
Question 3: What is the blast radius if one agent fails?
In a pipeline topology, one agent failure blocks all downstream agents. In a hierarchical topology, one worker failure affects only the subtask that worker owned, the supervisor can retry with a different worker or skip non-critical subtasks. In a peer-to-peer topology, one agent failure removes a capability, but other agents continue operating within their own scope. Understanding the blast radius of each agent’s failure determines how much isolation and fallback logic you need to build into the orchestration layer, which in turn influences which topology is operationally sustainable.
These three questions do not produce a mechanical answer, they produce a framing that makes the trade-offs explicit. The right topology is the one whose failure modes you understand and have designed mitigations for, not the one that feels most elegant on a whiteboard.
Human Oversight Integration
The decision about where humans sit in the orchestration graph is structural, not behavioral. It should be made during architecture design, not during incident response.
There are three positions where human oversight can be integrated into a multi-agent orchestration system.
At the task initiation boundary: A human reviews and approves the task decomposition before any agent executes. This is the highest-oversight position and appropriate for high-stakes, irreversible workflows, those where an incorrect decomposition would result in significant downstream harm that cannot be undone.
At specific stage boundaries: A human reviews the output of designated agents before those outputs are passed downstream. This is appropriate for workflows where certain agents produce outputs with significant semantic risk, outputs that encode consequential judgments, that will be acted upon by external systems, or that are difficult to validate programmatically.
At the final output boundary: A human reviews the final synthesized output before it is acted upon or delivered. This is the lowest-overhead position and appropriate when the workflow itself is well-understood and reliable, but the final output requires human judgment or accountability.
The mistake most teams make is treating human oversight as a dial that controls overall trust in the system, rather than as a set of structural checkpoints placed at specific high-risk boundary points. A system where every output requires human review is not an AI system, it is a human workflow with AI assistance. A system with no human checkpoints in irreversible workflows is not an AI system. It is an unmanned process with unknown reliability.
Human oversight integration belongs in the contracts-first design process. Each checkpoint is a contract: what the human is reviewing, what criteria determine approval versus rejection, and what the orchestration layer does with each outcome.
What Most Teams Get Wrong
The most common orchestration failure I see in production systems is treating the orchestrator as a smart router.
Teams spend considerable effort making the orchestrator intelligent, giving it the ability to choose between agents, to retry on failure, to balance load across parallel workers. These are all routing capabilities. The orchestrator gets very good at deciding where to send a task.
What it cannot do, in the absence of explicit contracts, is to decide whether what it received was a valid output in the first place. A router does not validate. It routes. A contract enforcer validates first, then routes, and if validation fails, it does not route at all. It escalates.
The specific capabilities that separate a contract enforcer from a smart router are:
- Schema validation at every inbound handoff, not just type checking, but semantic validation against the contract’s defined output constraints
- Precondition verification before every agent invocation, not just “is the agent available” but “is the system state valid for this agent to execute”
- Defined escalation paths for contract violations, not just retry logic, but the specific sequence of actions the orchestrator takes when an agent produces output that violates its contract
- Audit trail at every boundary, not just logs, but structured records of what was sent, what was received, and whether the contract was satisfied
Building these capabilities requires treating the orchestrator as a first-class engineering concern, not an integration afterthought. In most teams’ sprint planning, orchestration gets roughly as much design attention as the retry logic on an API call. It deserves as much design attention as the most critical service in the architecture.
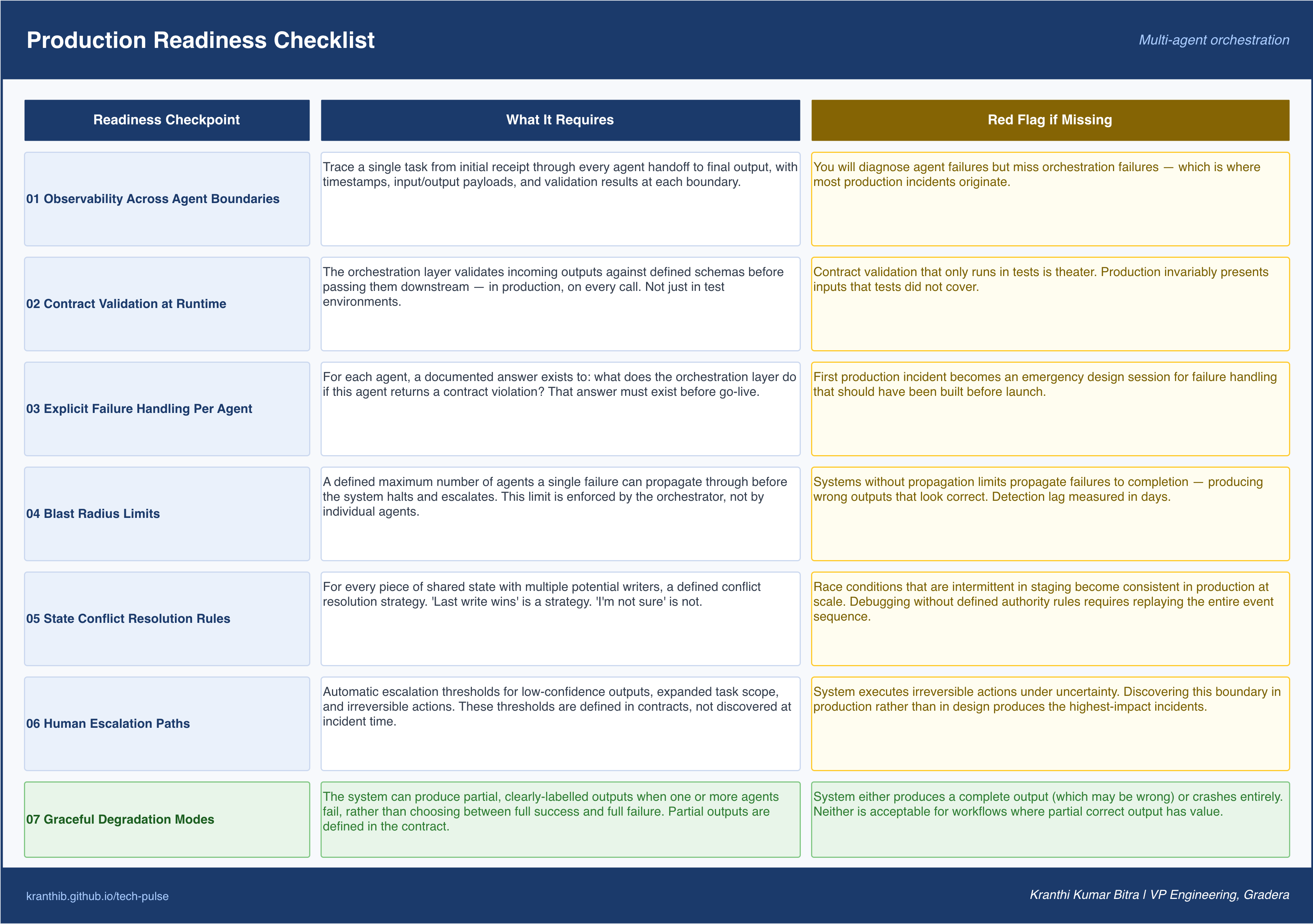
Production Readiness Checklist
A multi-agent system is not production-ready until it can answer yes to each of the following.
Observability across agent boundaries: Can you trace a single task from initial receipt through every agent handoff to final output, with timestamps, input and output payloads, and validation results at each boundary? If your observability stack sees agents individually but not the handoffs between them, you will diagnose agent failures but miss orchestration failures.
Contract validation at runtime: Does the orchestration layer validate incoming outputs against defined schemas before passing them downstream? Not in tests, in production, on every call. Contract validation that only runs in tests is theater.
Explicit failure handling for every agent: For each agent in the system, is there a documented answer to “what does the orchestration layer do if this agent returns a contract violation?” That answer must exist before the system goes to production, not after the first incident.
Blast radius limits: Is there a maximum number of agents a single failure can propagate through before the system halts and escalates? Systems without propagation limits will propagate failures to completion, producing wrong outputs that look correct.
State conflict resolution: For every piece of shared state with multiple potential writers, is there a defined conflict resolution strategy? “Last write wins” is a strategy. “Agent B’s output supersedes Agent A’s on field X” is a strategy. “I’m not sure” is not a strategy.
Human escalation paths: Does the system know when to stop and ask a human? Not just for errors, for situations where confidence is low, where the task scope has expanded unexpectedly, or where the output would trigger an irreversible action. Automatic escalation thresholds belong in the orchestration contracts.
Graceful degradation modes: Can the system produce partial, clearly-labeled outputs when one or more agents fail, rather than choosing between full success and full failure? A system that can report “compliance check incomplete, manual review required” is safer than a system that either completes successfully or crashes.
Figure 6. A production readiness lens for multi-agent systems: boundary observability, runtime contract checks, per-agent failure policies, blast-radius limits, shared-state conflict rules, human escalation, and graceful degradation.
Where This Is Heading
The current generation of multi-agent systems is solving the orchestration problem at the single-organization level. The next generation of the problem is cross-organizational orchestration, agents from different vendors, governed by different policies, operating under different trust models, coordinating on tasks that span organizational boundaries.
Emerging protocol standards for agent-to-agent communication are beginning to address this. The ability for agents to declare their capabilities, negotiate task parameters, and enforce contracts at the protocol level, rather than at the application level, is a structural improvement over bespoke orchestration logic. But protocol standards do not eliminate the contract design problem. They formalize it. The work of defining what an agent accepts, what it produces, and what it does when it fails remains a design discipline, not a protocol feature.
The teams building multi-agent systems today who invest in contract design discipline, who treat the orchestration layer as a first-class architectural concern rather than integration glue, are building systems that will compose cleanly with whatever the next generation of agent protocols looks like. The teams treating orchestration as routing are accumulating technical debt that will make that composition expensive.
Multi-agent architecture is not a technology problem. It is a systems design problem with an AI-shaped component. The teams that produce reliable, maintainable multi-agent systems in production are not necessarily the teams with the best models. They are the teams that applied the same rigor to agent interfaces that they would apply to any distributed system’s service contracts.
Conclusion
Single agents fail when they are overloaded. Multi-agent systems fail when orchestration is treated as routing. The discipline that separates production-grade multi-agent systems from sophisticated demos is contract design: defining what every agent accepts, produces, and does when it fails, before writing any agent logic.
The three orchestration topologies, hierarchical, peer-to-peer, and pipeline: each has appropriate contexts and specific failure modes. The topology choice is less important than the discipline applied to the contracts between agents within that topology.
The checklist for production readiness maps directly to the principles in this post: observability at boundaries, runtime contract validation, defined failure handling, blast radius limits, state conflict resolution, escalation paths, and graceful degradation. A system that satisfies all seven of these properties is production-ready regardless of its topology or complexity.
The post-mortem from the incident I described at the opening took a day to run and produced eleven action items. Exactly one of them was about agent logic. The other ten were about contracts.